

 2
2 0
0每经记者|李宇彤 每经编辑|魏文艺 艺术或许是人类世界中最复杂、最微妙的“视觉文本”之一。而当AI的视线投向这片由人类精神凝结的沃土时,将会发生什么? 1月20日,字节跳动旗下豆包与上海浦东 ...
|
每经记者|李宇彤 每经编辑|魏文艺 艺术或许是人类世界中最复杂、最微妙的“视觉文本”之一。而当AI的视线投向这片由人类精神凝结的沃土时,将会发生什么? 1月20日,字节跳动旗下豆包与上海浦东美术馆达成合作,正式成为该馆两项国际大展——“图案的奇迹:卢浮宫印度、伊朗与奥斯曼的艺术杰作”与“非常毕加索:保罗·史密斯的新视角”的官方AI讲解员。这也是AI产品首次以“官方身份”进驻美术馆。
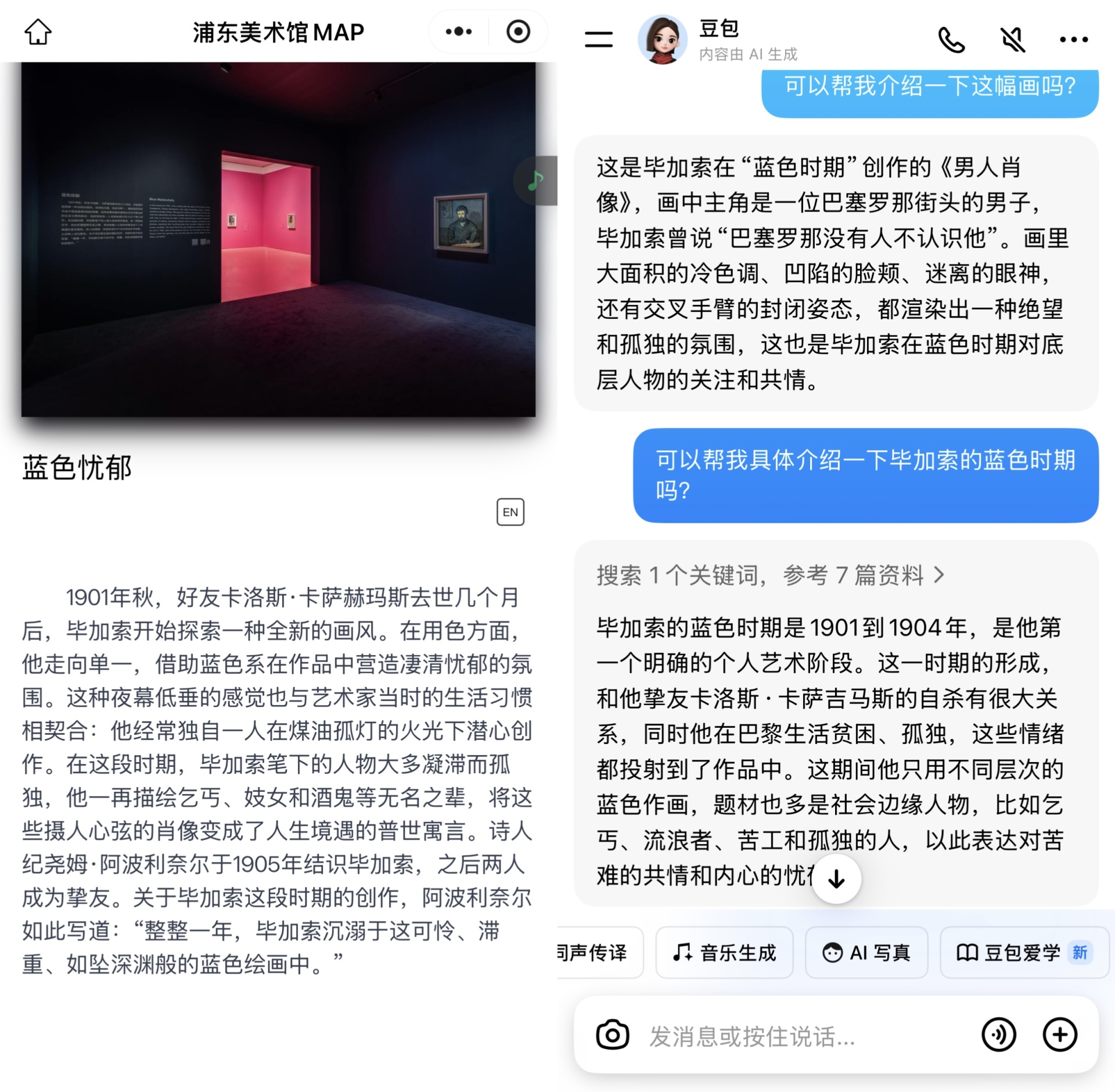
图片来源:每经记者 李宇彤 摄 这背后,是豆包大模型视觉理解能力的一次场景化落地。通过独家数据训练与定向搜索优化,在展厅中,豆包能辨识数百件展品,并支持观众连续、深入的追问式互动。 《每日经济新闻》记者(以下简称“每经记者”)注意到,从识别一幅画到理解一段文明,AI的“眼睛”正在变得愈发敏锐。随着行业竞争从文本生成转向视频理解与实时交互,一个能真正“看得懂、说得清”的大模型,成为在智能体(Agent)时代的竞争中的关键。而视频通话成为这项能力的集中展示场景。 2024年8月,智谱清言率先推出了国内首个面向C端(消费者端)开放的视频通话功能。而到了2025年,阿里“千问”同样配备了视频通话功能。 那么在实际运用中豆包表现如何?当AI的“眼睛”成为兵家必争之地,豆包又能否出奇制胜? 现场实测:豆包的识别、问答与它的“知识边界”在真实的观展场景中,观众的提问往往是开放而发散的。从“这是什么”的基础询问,到对创作背景、制作工艺的深入探讨,这类多层次、即兴的交互对AI的知识储备与实时解析能力构成了持续考验。 那么,豆包能否应对这样的挑战?每经记者在浦东美术馆进行了一次现场检验。 在基础信息层面,每经记者在“非常毕加索”展区请豆包介绍毕加索的“蓝色时期”,其回答不仅涵盖该阶段的具体时间,还关联到艺术家个人经历与时代背景。每经记者还将豆包的回答与浦东美术馆官方介绍进行了进一步核对,发现二者信息一致,但相较官方文艺的表达,豆包的表述更接近口语。
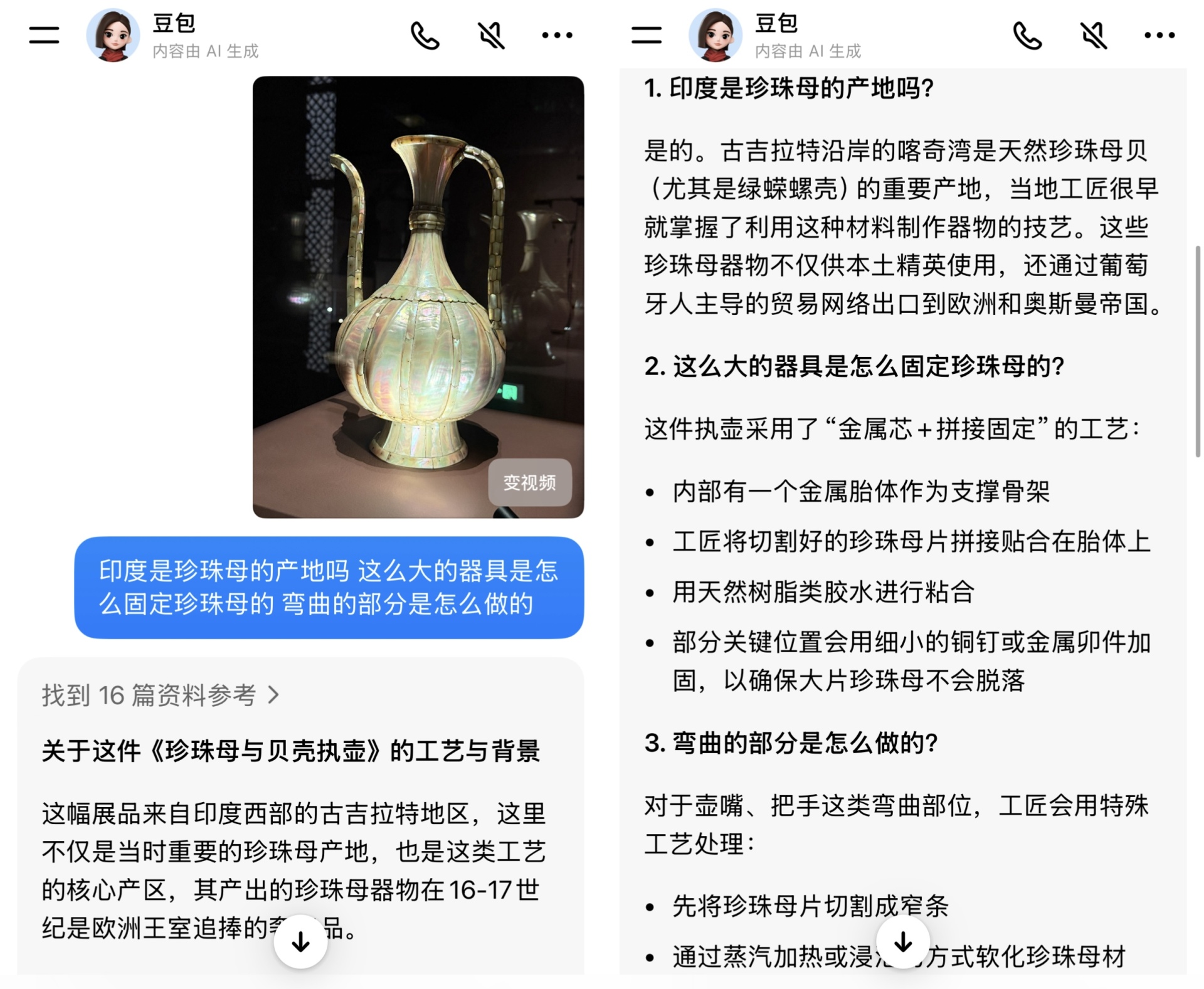
浦东美术馆官方介绍和豆包介绍 在识别能力上,每经记者发现即使刻意避开展签,豆包也能快速识别画作并给出介绍,这项能力在面对“图案的奇迹”中较为小众的展品时亦能保持精准。 当问题深入至技法与工艺细节时,豆包同样展现出结构化的解析能力。例如,面对毕加索画作《装扮成喜剧丑角的保罗》,它能结合艺术家当时初为人父的心境,阐释其风格转向与“未完成”笔触的创作意图。当每经记者在“图案的奇迹”展区指向一件印度作品《珍珠母与贝壳执壶》,接连抛出“珍珠母产地”“大器具如何固定”“弯曲部分如何制作”等具体工艺问题时,豆包也能从原料产地、工艺结构到历史流通背景逐层解答。
豆包对于《珍珠母与贝壳执壶》问题的回答 不过,在实际体验中,豆包作为解说员的表现仍会受到客观环境因素的制约。每经记者注意到,在手机信号较弱时,豆包难以完整、精确地识别语音提问的信息,但能依据对话上下文进行合理推断,给出大致对应的回复。 事实上,在走进美术馆之前,豆包的视频通话能力已在更广泛场景中经历了数月的实践打磨。2025年5月,豆包App上线基于视觉推理模型的视频通话功能,支持实时视频问答与联网搜索,迅速吸引了众多用户体验。 然而,从日常场景跨越到专业的美术馆场域,对豆包的识别精度与知识储备提出了更高维度的挑战。豆包逛展项目负责人坦言:“在博物馆场景中运用AI讲解,最大的挑战是保证内容的准确性。模型不仅要能区分外观高度相似的文物、理解小众且缺乏公开资料的展品,还要能在观众移动观展、从不同角度和距离观察同一件展品时,始终保持稳定识别。” 为此,豆包与浦东美术馆进行了独家数据合作与定向搜索优化,以此提升了文物识别与讲解的可靠性,并实现了支持连续、深入追问的交互体验。 据项目负责人介绍,该功能基于豆包视觉理解模型Seed 1.8的视觉语言理解能力。与早期“拍图—提问—再拍图”的断点式交互不同,该模型能持续理解观众移动中不断变化的视角和场景,实现近似于人与人之间的自然对话。 超越曝光:艺术馆合作背后的多模态深水区竞赛每经记者注意到,这不是豆包首次涉足文博领域。此前,豆包已与中国国家博物馆、河南博物院等七家国家一级博物馆达成合作,共同打造数字化看展体验区。但此次以“官方AI讲解员”身份参与,为豆包积累了稀缺的垂直领域经验,也为其视觉模型在复杂、高要求场景下的可靠性提供了背书。 豆包在美术馆中展现的“视觉能力”,背后是一场全球范围内加速演进的多模态AI竞赛,其中“视觉理解与实时交互”是当前关注的焦点。 2024年5月,OpenAI和谷歌接连发布“GPT-4o”和“Project Astra”两款具备实时语音、视频交互能力的产品之后,在国内市场,该赛道也被按下了加速键。同年8月,智谱清言面向用户推出视频通话功能,掀起了一轮测试热潮。而到了2025年,阿里面向C端市场上线的千问项目同样配备了视频通话功能。 随着竞争持续升级,行业对多模态价值的认识也逐步升级为衡量AI能否进入更深场景的标尺。 2025年12月,在火山引擎原动力大会上,火山引擎总裁谭待明确指出:“多模态其实代表着模型的应用进入更深的领域。”他在接受包括每经记者在内的媒体采访时阐释,现实中的需求常伴随视觉信息,工具返回的结果也多是视觉化的,只有具备视觉理解能力,模型才能像人一样操作工具、处理任务,从而极大地扩展适用边界。“我们很早就意识到,多模态才是模型真正成为复杂Agent的关键。” 在这一战略逻辑下,与浦东美术馆这类专业机构的深度合作,对豆包而言具有超越市场曝光的长期价值。 艺术展览场景知识密度高、且充满人文阐释空间。在此处深耕,既是对模型准确性与稳定性的测试,也是对其专业知识库的构建。而在艺术领域靠“分辨相似展品”修炼出的视觉理解与知识组织的能力,未来也可以迁移至教育、电商、设计乃至工业质检等更多需要精细化视觉辨别的行业。 此前,知名经济学者、工信部信息通信经济专家委员会委员盘和林在接受每经记者微信采访时曾表示,AI视频交互的使用前景非常光明,并且随着AI眼镜这一类符合视频通话应用场景的新硬件逐渐升温,AI视频交互还有更多的可能性。 免责声明:本文内容与数据仅供参考,不构成投资建议,使用前请核实。据此操作,风险自担。 封面图片来源:每经记者 李宇彤 摄 |
顶部






发布