













TMTPOST -- Alibaba Group unveiled Qwen 3 on Tuesday, a next-generation upgrade of its flagship AI model featuring enhanced hybrid reasoning capabilities.
Qwen3-235B-A22B, features 235 billion parameters but requires activating only 22 billion — roughly one-third the parameter size of DeepSeek-R1. This design dramatically cuts operating costs while achieving performance that surpasses leading models such as DeepSeek-R1 and OpenAI-o1, making it the most powerful open-source model available globally.
The announcement comes as China』s AI landscape heats up, driven by the rapid rise of local startup DeepSeek, which earlier this year claimed to deliver high-performing models at lower costs compared to Western rivals.
Baidu, China』s top search engine, also stepped up its efforts last Friday by launching the Ernie 4.5 Turbo and the reasoning-optimized Ernie X1 Turbo models.
Alibaba』s new Qwen 3 blends traditional AI tasks with advanced dynamic reasoning, offering a more flexible and efficient platform aimed at application and software developers.
Earlier this year, Alibaba had hastily introduced its Qwen 2.5-Max model in late January, shortly after DeepSeek』s breakthrough, touting it as delivering superior performance.

Qwen3 is trained on a massive dataset of 36 terabytes and undergoes multiple rounds of reinforcement learning during its post-training phase. It seamlessly integrates fast-thinking and slow-thinking modes while significantly enhancing capabilities in areas such as reasoning, instruction-following, tool utilization, and multilingual proficiency. These advancements set new performance benchmarks for all domestic and global open-source models.
Qwen3 includes a total of eight models, comprising two MoE (Mixture of Experts) models with 30 billion and 235 billion parameters, as well as six dense models with 0.6 billion, 1.7 billion, 4 billion, 8 billion, 14 billion, and 32 billion parameters. Each model achieves state-of-the-art (SOTA) performance within its size category among open-source models.
Notably, the 30B parameter MoE model of Qwen3 delivers over a 10-fold improvement in model efficiency, requiring activation of only 3 billion parameters to match the performance of the previous generation Qwen2.5-32B model. Meanwhile, the dense models of Qwen3 continue to push boundaries, achieving high performance with half the parameter count. For instance, the 32B version of Qwen3 surpasses the performance of the Qwen2.5-72B model across tiers.
April has been a month of concentrated releases in the large model space. OpenAI introduced its GPT-4.1 o3 and o4 mini series models, Google launched its Gemini 2.5 Flash Preview hybrid reasoning model, and Doubao announced its 1.5·Deep Thinking model. Other major players in the industry have also open-sourced or updated numerous models. There are even rumors circulating about the imminent release of DeepSeek R2, though most of these reports remain speculative.
Regardless of whether DeepSeek R2 is released, Qwen3 has taken the lead, positioning itself as the true starting point for the "popularization" of large models.
China's First Hybrid Reasoning Model Enhances Agent Capabilities and Supports MCP
The Qianwen 3 model supports two distinct reasoning modes:
- Slow Thinking Mode: In this mode, the model performs step-by-step reasoning and provides a final answer after careful deliberation. This approach is ideal for tackling complex problems that require deep thought.
- Fast Thinking Mode: In this mode, the model delivers rapid, almost instantaneous responses, making it suitable for simple problems where speed is prioritized over depth.
All Qianwen 3 models are hybrid reasoning models, making them the first of their kind in China. This innovative design integrates "Fast Thinking" and "Slow Thinking" into a single model. For straightforward tasks, it can provide instant answers with low computational power, while for complex issues, it can engage in multi-step "Deep Thinking", significantly reducing computational resource consumption.
The API allows users to customize the "Thinking Budget" (i.e., the maximum number of tokens allocated for deep reasoning), enabling different levels of thought processes to flexibly meet the diverse performance and cost requirements of AI applications across various scenarios. For instance:
- The 4B model is an excellent size for mobile devices.
- The 8B model can be smoothly deployed on computers and automotive systems.
- The 32B model is highly favored for large-scale enterprise deployments, and developers with the necessary resources can easily get started.
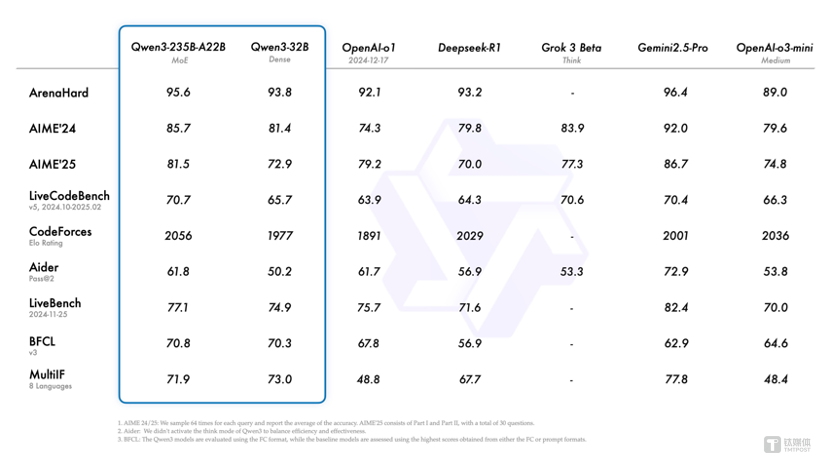
In the AIME25 evaluation, which measures mathematical problem-solving skills at an Olympiad level, Qianwen 3 scored an impressive 81.5, setting a new record for open-source models. In the LiveCodeBench assessment, which evaluates coding capabilities, Qianwen 3 surpassed the 70-point threshold, outperforming Grok3. Additionally, in the ArenaHard evaluation, which assesses alignment with human preferences, Qianwen 3 achieved a remarkable score of 95.6, surpassing OpenAI-o1 and DeepSeek-R1.
While performance has significantly improved, the deployment cost of Qianwen 3 has drastically decreased. The full-powered version of Qianwen 3 can be deployed with just four H20 GPUs, and its memory usage is only one-third that of models with similar performance.

The Qwen-3 model supports 119 languages and dialects. Currently, these models are open-sourced under the Apache 2.0 license and are now available on platforms such as Hugging Face, ModelScope, and Kaggle.
Alibaba also recommends deploying the model using frameworks like SGLang and vLLM. For local usage, tools such as Ollama, LMStudio, MLX, llama.cpp, and KTransformers are supported.
Qwen-3 also focuses on the application of intelligent agents and large language models. In the BFCL evaluation for assessing agent capabilities, Qwen-3 achieved a new high score of 70.8, surpassing top-tier models like Gemini2.5-Pro and OpenAI-o1. This breakthrough significantly lowers the barrier for agents to utilize tools effectively.
Additionally, Qwen-3 natively supports the MCP protocol and boasts powerful function-calling capabilities. Combined with the Qwen-Agent framework, which includes pre-built tool-calling templates and parsers, it greatly reduces coding complexity and enables efficient agent operations on mobile phones and computers.
36 Trillion Tokens Pre-Trained, Four-Stage Fine-Tuning
In terms of pre-training, the Qwen-3 dataset has undergone significant expansion compared to Qwen-2.5. While Qwen-2.5 was pre-trained on 18 trillion tokens, Qwen-3 nearly doubles this amount, reaching approximately 36 trillion tokens.
To construct this massive dataset, the Qwen team not only collected data from the internet but also extracted information from PDF documents. For instance, Qwen-2.5-VL was used to extract text from these documents, and Qwen-2.5 further improved the quality of the extracted content.
To enhance the quantity of mathematical and coding data, the Qwen team utilized specialized models like Qwen-2.5-Math and Qwen-2.5-Coder to synthesize data. This synthesized data includes diverse formats such as textbooks, Q&A pairs, and code snippets.
The pre-training process is divided into three stages. In the first stage (S1), the model was pre-trained on over 30 trillion tokens with a context length of 4K tokens. This stage equipped the model with foundational language skills and general knowledge.
In the second phase (S2), the Qwen team improved the dataset by increasing the proportion of knowledge-intensive data, such as STEM, programming, and reasoning tasks. Subsequently, the model underwent pre-training on an additional 5 trillion tokens.
In the final phase, the Qwen team extended the context length to 32K tokens using high-quality long-context data, ensuring the model could effectively handle longer inputs.

Due to improvements in the model architecture, increased training data, and more efficient training methods, the overall performance of the Qwen3 Dense base model is comparable to the Qwen2.5 base model, which has more parameters.
For instance, Qwen3-1.7B/4B/8B/14B/32B-Base performs on par with Qwen2.5-3B/7B/14B/32B/72B-Base. Notably, in areas such as STEM, coding, and reasoning, the Qwen3 Dense base model even surpasses the larger-scale Qwen2.5 models.
As for the Qwen3 MoE base models, they achieve performance similar to the Qwen2.5 Dense base models while using only 10% of the activated parameters. This results in significant savings in training and inference costs.
Regarding post-training, to develop a hybrid model capable of both reasoning and rapid response, the Qwen team implemented a four-phase training process. This process includes: (1) cold start for long reasoning chains, (2) reinforcement learning for long reasoning chains, (3) integration of reasoning patterns, and (4) general reinforcement learning.

In the first phase, the model was fine-tuned using diverse long reasoning chain data, covering various tasks and domains such as mathematics, coding, logical reasoning, and STEM problems. This process aimed to equip the model with fundamental reasoning capabilities.
The second phase focuses on large-scale reinforcement learning, utilizing rule-based rewards to enhance the model's exploratory and analytical capabilities.
In the third phase, the model is fine-tuned on a combined dataset that includes long-chain reasoning data and commonly used instruction-tuning data. This process integrates non-thinking patterns into the reasoning model, ensuring a seamless combination of reasoning and rapid response capabilities.
During the fourth phase, reinforcement learning is applied across more than 20 general domains, including tasks such as instruction compliance, format adherence, and agent capabilities. This step further enhances the model's general-purpose abilities while correcting undesirable behaviors.
Currently, individual users can directly experience Qianwen 3 through the Tongyi App, and Quark is set to fully integrate Qianwen 3 soon. Alibaba Tongyi has already open-sourced over 200 models, with global downloads exceeding 300 million. The number of derivative models from Qianwen has surpassed 100,000, overtaking the U.S.-based Llama to become the world's leading open-source model.












