














DeepSeek 猝不及防地更新了,不是 R2,而是 R1v2。
官方的通告也很 「DeepSeek」,甚至可以说有点佛系,在微信交流群发了一句:
「DeepSeekR1 模型已完成小版本试升级,欢迎前往官方网页、APP、小程序测试 (打开深度思考),API 接口和使用方式保持不变。」
看起来平平无奇,但真一顿实测下来,这个 「小版本」 恐怕还是过于谦虚了。
全球最大 AI 开源社区 HuggingFace 已经开源了这个新版本,名字也很实在:DeepSeek-R1-0528。不过截至目前,模型卡还没同步更新。
有需求的开发者可以自己动手部署,附上开源地址:https://huggingface.co/DeepSeek-ai/DeepSeek-R1-0528/tree/main
特点总结:
-
推理能力大幅提升,代码水平暴涨;
-
写作表现更有人味,格式更规范;
-
思考过程不仅快,还有条理、讲逻辑;
-
支持长时间思考,一项任务可持续 30 到 60 分钟。
根据编码基准测试 LiveCodeBench 的最新结果,这一版 R1 的表现已经和 OpenAIo3High 已经五五开了,而且,它的进步也远不止于代码能力。

当然,验证一款模型是否真正 「可用」,还得看它在真实场景下的表现,我们也照例跑了几个案例。
编程:网页、游戏、UI,啥都能做
【扫雷游戏】 考察编程、逻辑推理
比方说,我们参考网友 @ty_1215 的提示词,让新版 R1 设计一个扫雷游戏,结果不但逻辑完整,生成代码结构工整,直接就能拿来跑。
虽然这个任务比较简单,但在逻辑推理和编程结构的处理上,也算是超出了我的预期。

【音乐播放器】 考察审美、功能规划
再让它模仿 QQ 音乐播放器的 UI 设计,给它指个方向,它咔咔就是一通输出,不仅有播放器主体,还带歌词、播放按钮、封面图、进度条。
理解任务只是基本操作,但拆解指示设计出符合审美且功能完整的界面就难上加难了,最终交出的成果也给我一种它能做得更好的既视感。
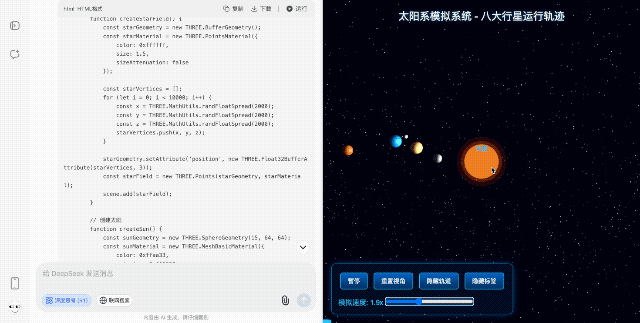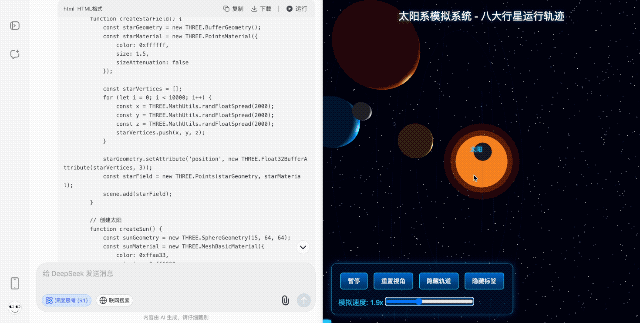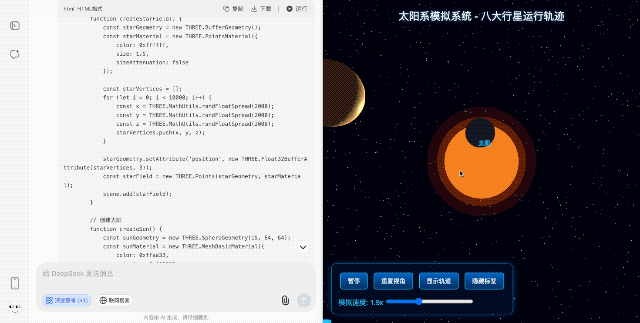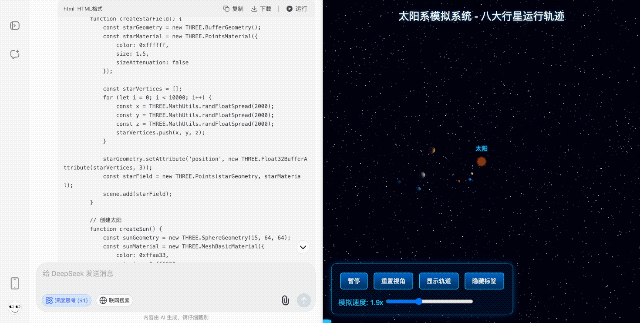
【太阳系模拟】 考察图形渲染和物理模拟
再放飞一点,让它模拟一个太阳系,包括太阳、八大行星和月球,能展示公转轨道、自转动画,还要求背景得带上动态的星星。
生成的效果虽然颜色配得土了点,但搭配漫天的星星,整个空间氛围感直接拉满,尤其是那个可缩放可旋转的视角,完全可以作为中小学科普动画的原型演示。
写作:喜大普奔,终于不油腻啦
【风格模仿】 考察写作、深度理解
除了写代码,新版 R1 写文章的水准也有大幅度提升。一句话概括,就是更有人味了。
春节期间,我们让 DeepSeekR1 以 《百年孤独》 的风格写春节面对七大姑八大姨的故事,当时就发现,旧版 R1 文笔最大的毛病太爱堆砌意象,拽大词,读着有点油。

这次用 R1v2 复刻同一个问题,风格明显收敛不少,语言更自然,意象不突兀,有文学感但不矫情,读起来更自然了。
最近看到一句文言文版的 「懂的都懂」,我心想,新版 R1 停留在字面意思就已经实属不易了,结果出乎意料,它不仅提供字面意思,还深挖了个深层含义,以及甚至从哲学角度开始思考。
类似的,我们 3 月份的时候让 DeepseekR1 对 《红楼梦》 脂批中的 「情榜」 进行解读,发现它的深度思考过程逻辑性较弱,零散地整合了不同网页的观点。
而且,「泛灵论」「理性超越」「异化」 等非口语化的词汇还是频繁出现,分析内容也较为机械干瘪。


这次拿同样的问题问 R1v2,观察它的深度思考过程,发现思考过程的逻辑性更清楚完整,不再是对网页信息的零散整合,且有关注到 「用户可能没意识到但值得深挖的点」。
最重要的是,它在生成回答时自行 「注意避免学术腔」,也添加了生动的场景例证。


思维链及推理:依然靠谱,还更清楚
语言能力的进步,不仅对于文本生成很重要,更加是渗透在每个环节——尤其是思维链。
思维链反映的是模型是怎么想的、为什么得出这个结论,以及它怎么表达自己这一系列经过。
DeepSeek 这次的升级,并不只是 「答对题」 这么简单。更重要的是,它在推理路径上的一些细节变化,开始显露出新的能力结构。
【鸡兔同笼】:考察推理理解、解法多样性

鸡兔同笼是非常经典的 「必考题」,没有模型能逃得过。新 R1 的表现展现出很好的稳健性:一开始用设元+解方程,体现出结构化建模能力。后面补了一种逻辑回推法——一种典型的奥数思维训练套路。

两种方法互补,验算结果,保证正确。在整个思维链展开中,每一个变量意义、每一步计算、每一个代入都交代得明明白白。尤其是中间过程的口语化表达,非常适合给不那么擅长数学的读者阅读。
不过,整个过程里没有出现自我纠错?这不应该啊,再上个题试试。
【计算时针角度】 考察混合题型、基本几何知识

这题看下来,可以拍着良心说,CoT 的进步相当明显。
首先有清晰的结构意识,先讲 「表面方法」,用基本角度计算;再引入 「常用公式」 进行验证;最后还能进行反向校正,验证。

「时针角度」 的计算是非常理想的模型测试题,因为除了要计算数值,也要有简单的几何概念。新 R1 不仅能完成计算,还体现基本的几何空间感。
整个过程中,多次出现了 「我再确认一下」「有时候会有人算错」「我可能漏掉了什么」 这些自查,说明模型现在并不只是一股脑的列数据,而是有 「我正在思考」 的姿态——虽然只是姿态,但这不就是 CoT 的核心吗?
【语义陷阱推理】 考察分词能力、嵌套推理拆解
这看似一个脑筋急转弯,但实际上,所谓的 「真话假话」 之间互相嵌套,在推理上要真正理解 「最少」 和 「最多」 的语义。
这也就意味着不能武断地分词,必须考虑每一种情况。因此这道题的思维链和解答都是最长的——超过了四千字。

语义理解没有翻车,这点很不错。从两个互斥的假设出发,来一点点完成推理,考虑了尽可能多种场景和可能性。
在 「总是说谎」 这个条件解释上,新 R1 没有过多解释。实际上,中文里它是会引发歧义的,「总是」 二字会误导模型以为是 「过去一直都说谎」 而非 「当下说谎」。它这次没踩坑,可能有一定概率是靠 「幻觉」 躲过去了。
不过,这一题是真实暴露出了问题:无论是思维链,还是最后的解答,叙述方式都是典型的 「语言模型思维链+流水账排查」,写得跟个五年级数学作业一样,洋洋洒洒也啰啰嗦嗦……

如果生成一个链条图、思维导图,可能会更清楚。
总体来说,新 R1「脑子」 比以前清楚了,推理一如既往的靠谱。在代数推导、假设排除等环节表现稳定。推理路径整体连贯,基本能准确理解语义陷阱类题目中的逻辑关系。
思维链的表现来看,相比于之前的略显冰冷的 「理工脑袋」 叙述方式,这一次的 CoT 有点像是把模型的 「脑内小剧场」 摆了出来。但要更贴近 「人类思维风格」 的表达,还需在精炼、组织与重点识别上继续优化。
除了我们的测试,网友们的反馈也进一步验证了新版 R1 的进步。
以经典的小球测试为例,从网友 @flavioAd 发的测试结果来看,新旧模型差距相当明显:旧版 R1 的球动作生硬、弹跳粘线,像是被钉死在轨道上;新版 R1 的球运动更自然、重力感更强。
用网友的话来说,「这个新版的球有自我意识,自己决定什么时候弹跳」

另一个测试来自博主 @karminski3,他拿 DeepSeek-R1-0528 和 Claude-4-Sonnet 测试了一个球体撞墙的案例。
同样的提示词,Claude 输出了 542 行代码,DeepSeek 直接来 728 行,功能更全、细节更细,尤其是控制面板的配色、反射、FPS 表现……有点工业设计作业的即视感。

模型的基础常识能力在此次更新中有所升级。网友 @Yuchenj_UW 提到,DeepSeek-R1-0528 是目前唯一一个能稳定正确回答 「9.9-9.11 等于多少?」 的模型。
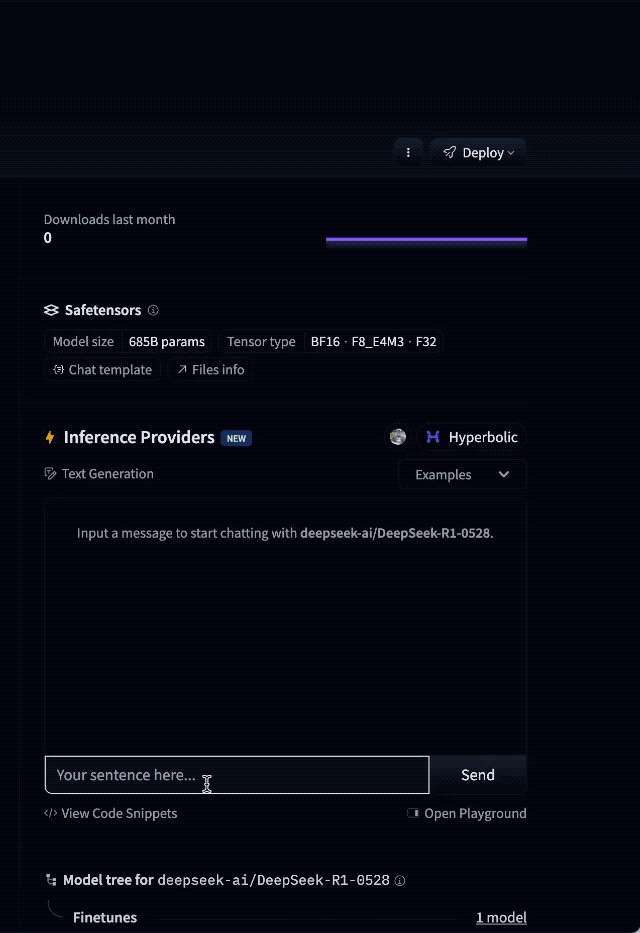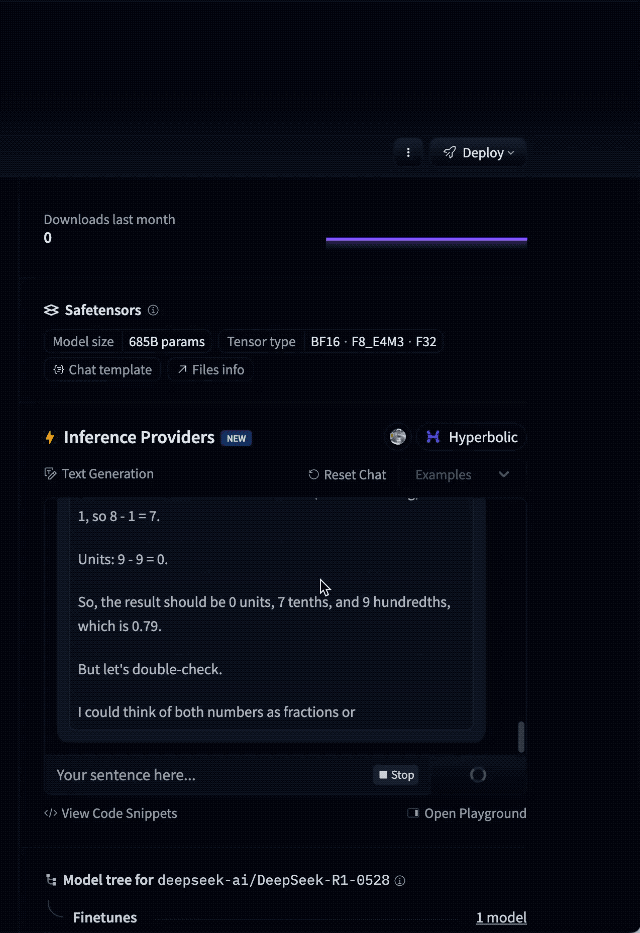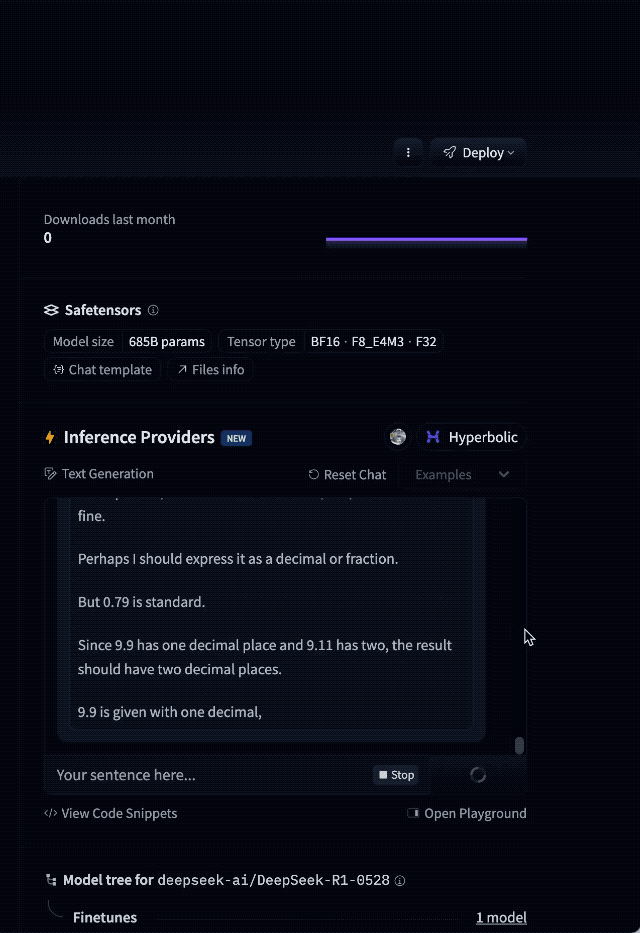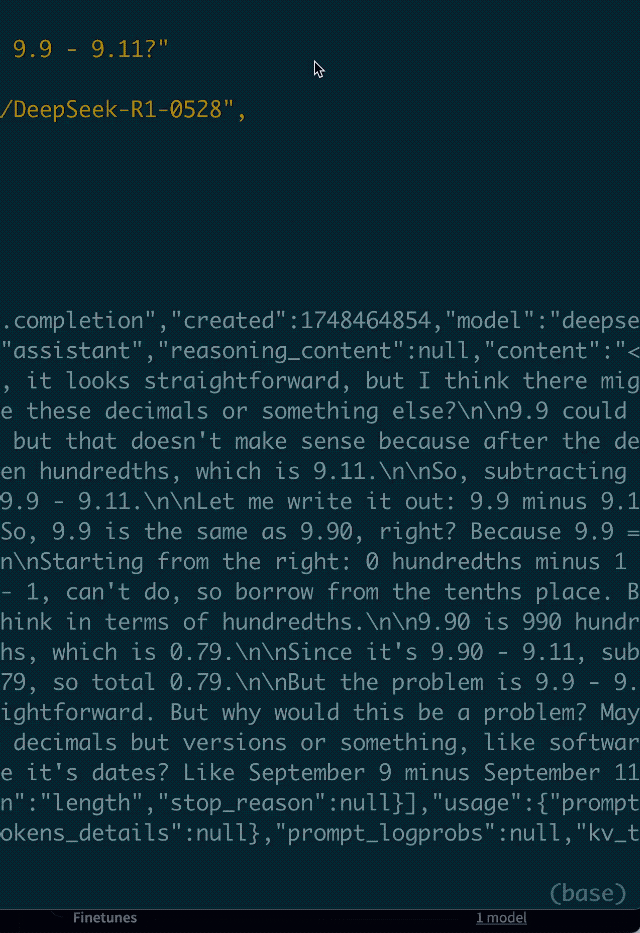
网友的梗也没落下。有人调侃 DeepSeek 写代码像 freestyle:如果数学天才陶哲轩 DeepSeek 强强联合,说不定真能出个 「专辑」。当然,他所说的专辑不是音乐,而是一份能解决当代数学难题的论文。

知名 X 博主 @slow_developer 也加入了实测阵营,称赞 「DeepSeek 真是王者归来……」 他为 R1v2 设计了一道中等复杂度的任务:构建一个单词评分系统。
DeepSeekR1 简单思考了一下,一次性生成两个文件,一个是主程序,一个是测试脚本,代码结构清晰,逻辑闭环,首次运行就顺利通过,没有报错。

目前据他测试,只有 OpenAI 的 o3 模型曾经能做到这种稳定输出,DeepSeekR1v2 是第二个。
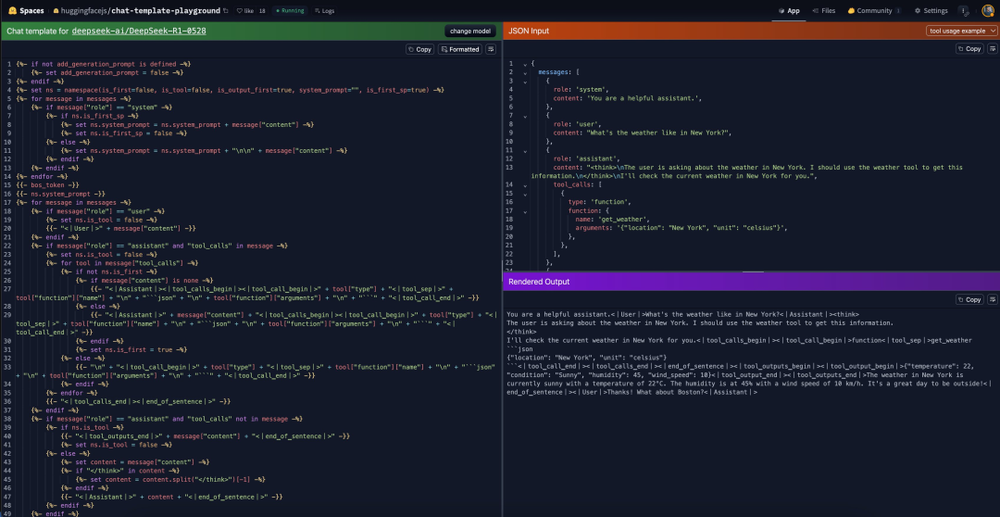
网友 @mishig25 的案例则演示了 R1v2 在 HuggingFacePlayground 上完整跑通 ChatTemplate,实现结构化函数调用的过程。
从解析用户意图、触发具体函数,到最后组合成回答的完整流程,DeepSeek 全程干净利落,表现出极强的指令理解+执行能力。
简言之,别被 DeepSeek-R1-0528 这个朴实无华的名字忽悠了。
坏消息是,新版 R1 的发布意味着 R2 恐怕还得再等等,好消息是,新版 R1 表面看着是个 「小版本」,实则是一次能打的真升级,不管是可用性、稳定性,还是复杂任务的完成度,全都肉眼可见地往上抬了一档。
如果你还在苦等 R2,不妨先认真看看 R1v2。用过一次,就真的回不去了。不过 DeepSeek 啊,咱就是说... 那 「服务器繁忙」 的提示,能少点不?
模型是好用,咱也得能用上才行啊!












