













猜您喜欢



全球正爆发一场新的 AI 算力变革。
今年 7 月初,AI 芯片巨头英伟达市值首次突破 4 万亿美元 (约合人民币 28 万亿元) 大关,成为全球市值最高的人工智能、半导体和科技领域的企业。同时,英伟达 CEO 黄仁勋身价也增至 1440 亿美元,超越 「股神」 巴菲特,成为全球资本市场的焦点。
这一现象背后,不仅仅是个别企业的成功故事,更是 AI 时代全球科技、资本市场格局变化,还预示着 AI 算力和基础设施对于 AI 产业发展的重要性。
而对于国内市场来说,这一轮 AI 算力热是一次重要的机遇。一方面,国内面临 AI 算力封锁挑战;另一方面,DeepSeek 等中国 AI 大模型发展迅猛,对于 AI 推理算力需求增加,但国产 AI 芯片产能不足、具有较大缺口。
据统计,预计到 2030 年左右,中国 AI 芯片市场规模可能超过 1.3 万亿元,届时中国 AI 产业及相关行业可能将价值 1.4 万亿美元 (约合人民币 10 万亿元)。
那么,如今 「后摩尔时代」 下,中国 AI 芯片行业如何学习 DeepSeek 这种以效率为导向、低成本发展模式,开辟一条独特的发展路径,用新技术突围算力封锁,从而提升国产 AI 算力技术和生态?
7 月初举行的中国集成电路设计创新大会 (ICDIA) 上,清华大学教授、集成电路学院副院长、清微智能联合创始人兼首席科学家尹首一发表题为 《AI 时代芯片设计的 STCO 挑战》,提出了一个非常新颖的 STCO(System-Technology Co-optimization)「系统技术协同优化」 的方法,通过对系统、目标需求建模,希望整合芯片设计、制造工艺、封装技术等多个环节,从而实现 AI 芯片性能、功耗、面积、成本 (PPAC) 的最优平衡。
芯片系统技术协同优化解决算力 「十字路口」
AI 技术进入大众视野到今天已经十三年,大体分为三个阶段:
- 第一阶段:2012 年-2017 年之间,关注一个具体、 受限的 AI 任务,如图像识别;
- 第二阶段:2018 年以后,AI 大模型领域的 「过渡期」 形成了非常关键的技术,比如 Transformer 架构,但当时的 AI 模型参数规模并没有特别大;
- 第三阶段:2020 年至今,我们进入大模型的时代,AI 模型和规模急剧扩张,大规模参数的模型结构更复杂,适用于多任务学习,具备更好的性能和泛化能力。
如今,AI 大模型发展的背后,芯片算力必不可缺,今天 AI 需求的算力是供给的 100 倍左右。而三要素——计算架构、制造工艺、芯片面积相乘,就构建出强大的芯片算力。
然而,当前国内 「制造工艺」 受限,芯片性能增长已进入 「瓶颈期」。而且,集成电路产业进入 「后摩尔」 时代,从原来单一芯片设计到如今 「软件+系统设计」,致使芯片算力技术发展进入到 「十字路口」。
事实上,随着芯片制程和功耗要求越来越高,技术需求越来越复杂,所谓 「价格不变时集成电路上可容纳的晶体管数目每隔 18-24 个月增加一倍、性能也将提升一倍」 这一定律已不太可能会实现,制造工艺面临物理极限,工艺红利带来的算力提升已难以为继,市场呼唤新的技术突破。同时,先进工艺封锁、先进 HBM(高带宽存储) 封锁也成为 AI 芯片算力发展的新挑战。
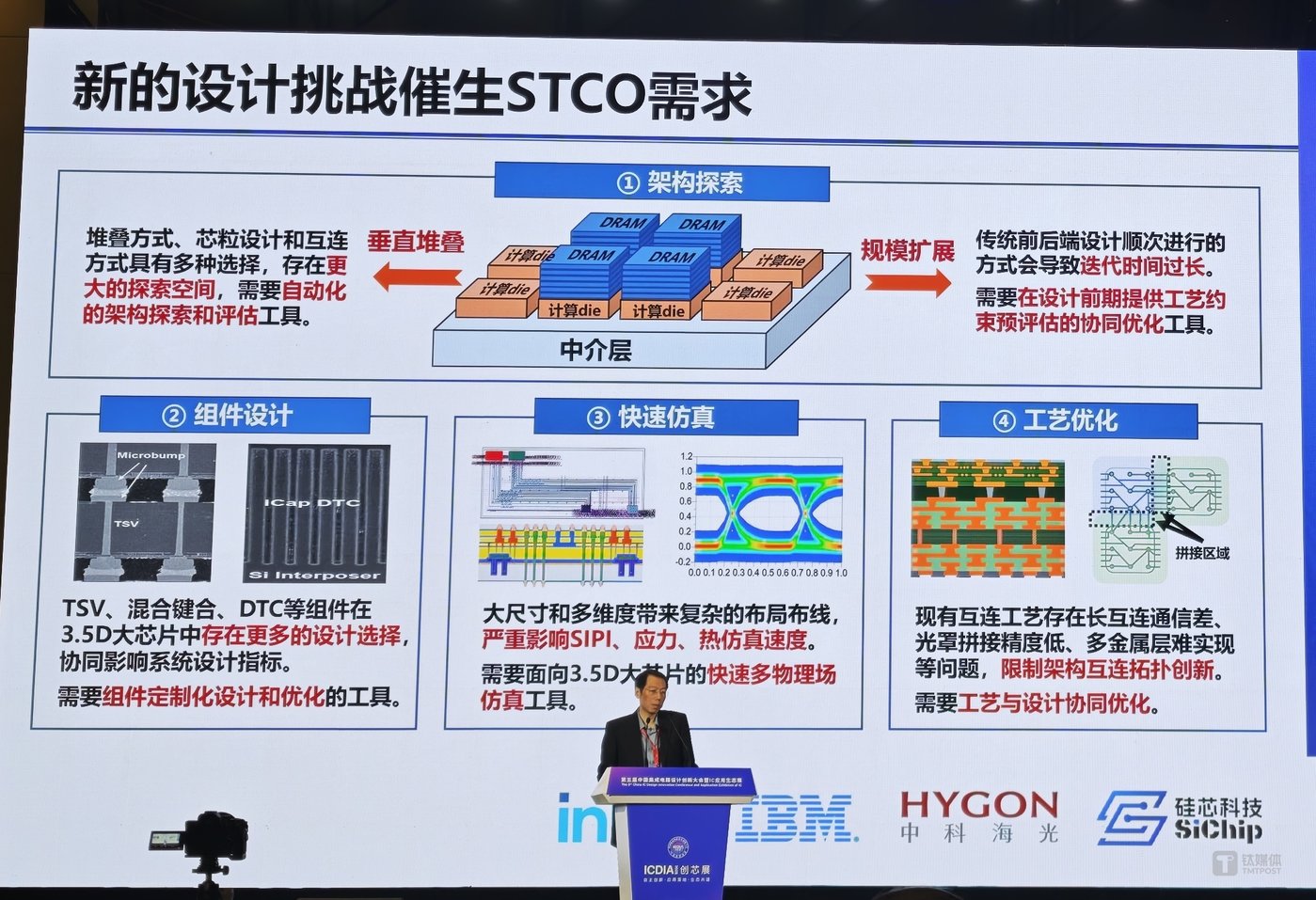
因此,尹首一教授提出,利用 STCO(系统技术协同优化) 技术方法,整合架构探索、组件设计、快速仿真、工艺优化等先进集成技术设计手段,从而带来全新芯片算力提升的新空间,不仅实现 AI 芯片性能、功耗、面积、成本之间的最优平衡,而且可有效突破算力封锁。
1、架构探索:
- 垂直堆叠:堆叠方式、芯粒设计和互连方式具有多种选择,存在更大的探索空间,需要自动化的架构探索和评估工具。
- 规模扩展:传统前后端设计顺次进行的方式会导致迭代时间过长,需要在设计前期提供工艺约束预评估的协同优化工具。
2、组件设计:3.5D 大芯片中存在更多的设计选择, 协同影响系统设计指标。在 3.5D 大面积集成下,供电分布网络 (PDN)、深沟槽电容 (DTC) 规模庞大,存在协同优化难的问题,同时三维集成架构中,TSV(硅通孔技术) 承载着信号、供电等重要作用,与机械应力等问题息息相关,需要仔细权衡 TSV 设计与芯片性能、良率的关系。因此,芯片设计过程中需要组件定制化设计和优化的工具。
3、快速仿真:在 3.5D 高密度集成下,现有设计流程无法提前考虑大规模翘曲,导致迭代周期长成本高,且现有工具难以支撑 3.5D 大规模封装力学仿真问题,因此,未来芯片研发需要高抽象层次的预评估方法,以及针对 3.5D 规模的快速多物理场力学仿真 EDA 工具。
4、工艺优化:现有互连工艺存在长互连通信差、光罩拼接精度低、多金属层难实现等问题,限制架构互连拓扑创新,所以芯片设计过程中需要工艺与设计协同优化。
尹首一表示,AI 时代,我们设计一款 3.5D 大芯片面临的四部分芯片设计挑战,可以总结为三个层次的痛点,从而迫切需要我们在芯片设计方法学、设计工具上有所突破:
- 1、我们今天暂时对一些问题缺乏设计及评估工具,在这种情况下只能靠经验驱动,依赖于人工经验,从而带来性能的急剧下降;
- 2、设计芯片中确实有一部分的基础工具,但是存在仿真慢、迭代长等问题,尚无法满足设计周期需求;
- 3、今天对 STCO 设计空间探索尚不全面,造成今天一部分设计芯片没有找到最佳的性能和设计决策点。
尹首一强调,上述痛点既是未来在 AI 时代设计算力大芯片亟需突破的问题,也给一些领域带来了新的机会,希望芯片技术发展过程中,可以在设计、工具、工艺三方面充分协同起来,能够完美解决一些挑战,并且满足设计中的需求,为未来 AI 芯片算力供给提供最坚实的基础和保障。
未来 AI 算力非 GPU 架构加速崛起
随着 AI 和大数据技术的广泛应用,中国芯片算力规模已呈现快速增长态势。
据弗若斯特沙利文统计,2024 年,中国 AI 计算加速芯片市场规模 1425.37 亿元,到 2029 年激增至 13367.92 亿元,期间年均复合增长率 53.7%。同时,2024 年中国算力总整体规模达 617.00EFLOPs,预计到 2029 年达 3442.89EFLOPs,年均复合增长率 40%,其中,智能算力 2025 年-2029 年期间年均复合增长率高达 45.3%。
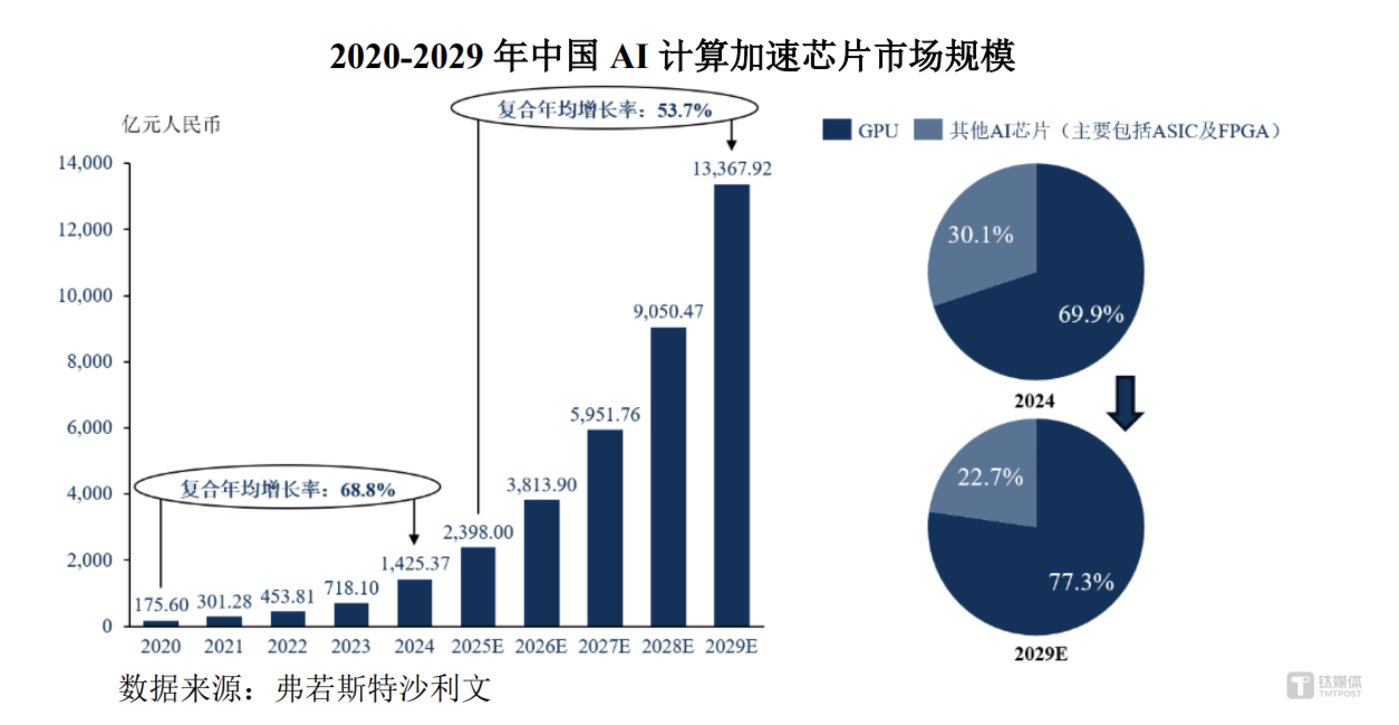
但与此同时,从数据来看,当前国内 GPU 芯片的市场占比 69.9%,而其他 AI 芯片占比为 30.1%。相对于弗若斯特沙利文给出未来 22.7% 的比例预期,IDC 却认为,预计到 2028 年,中国加速计算服务器市场规模将超过 550 亿美元,非 GPU 架构服务器市场占比将迎来快速增长。
值得一提的是,一种与英伟达 GPU 共享式集中计算模式不同,基于分布式数据流计算的新型计算架构——可重构 RPU(Reconfigurable Processing Unit),近年来随着 AI 大模型发展异军突起。
它与 CPU 的冯·诺依曼指令驱动时域计算模式不同,是一种数据驱动的时空域执行模式,可根据不同的应用需求重构硬件资源,构建专用的计算通道,天然适配 AI 算法模型并行化、流式化、密集化特点,使得 AI 芯片具备灵活性和专用集成电路高效性的优势。2015 年,国际半导体技术路线图 (ITRS) 将可重构芯片列为 「未来最具前景芯片架构技术」,可重构芯片也被学术界和产业界视为 CPU、FPGA 和 GPU 之外的第四类通用计算芯片。
放眼全球,该类型架构芯片呈现蓬勃发展态势。例如,美国斯坦福大学孵化的公司 SambaNova,通过自研的可重构芯片产品成为 AI 芯片行业估值最高的独角兽公司,其产品能够支持 5 万亿参数模型训练,8 芯片配置性能为英伟达 H100 的 3.1 倍;美国芯片初创公司 Groq 开发的张量流式处理器架构 LPU(Language Processing Unit),推理速度相较于英伟达 GPU 提高 10 倍,成本却降低至英伟达的十分之一;特斯拉在专为 AI 训练自研的Dojo 超算系统中也采用了分布式数据流计算方式,单个 Dojo 拥有 9Petaflops 算力、每秒 36TB 带宽,目前是特斯拉实现通用人工智能 (AGI) 的核心基础设施。
分布式数据流计算不仅在技术层面持续实现突破,在产品商业化方面也取得了阶段性成果。近期,OpenAI 租用谷歌 AI 芯片 (TPU) 训练 ChatGPT,首次采用了 「GPU 训练+TPU 推理」 的混合架构模式。今年 4 月,谷歌最强 AI 芯片第七代 TPU(张量处理单元)——Ironwood 正式亮相,这款 TPU 芯片性能狂飙 3600 倍,直接叫板英伟达 Blackwell B200。
据 Capvision 显示,谷歌 TPU 集群中,70%-80% 的算力用于内部业务场景,剩余不到 30% 以租赁方式对外使用。而其中,全球超过 60% 的生成式 AI 初创公司、近 90% 生成式 AI 独角兽都在使用谷歌云 TPU AI 基础设施服务。
国内专注可重构 RPU 芯片的代表企业包括清微智能。
作为 「脱胎」 于清华可重构实验室的 AI 芯片公司,清微智能基于国产原创可重构芯片 (RPU) 架构研发并量产了高算力芯片 TX8 系列,面向智算中心等云计算场景,其最新 TX81 单个 RPU 模组算力可达到 512TFLOPS(FP16),庞大的 REX1032 训推一体服务器单机算力可达 4 PFLOPS,单机可支持 DeepSeek R1/V3 满血版推理,支持万亿以上参数大模型部署,可实现千卡直接互联,无需交换机成本。目前,清微智能已在国内多个省份落地千卡智算中心,同时在多个行业实现服务器部署。
总结来看,国内 AI 算力缺口很大、市场需求持续增长。长期来看,未来 AI 芯片核心架构的内在属性需要与 AI 模型特点相适配,同时要结合架构探索、组件设计、快速仿真、工艺优化等先进集成技术设计手段进行 STCO,不断迭代,换道超车,才能有望突破当前英伟达 GPU 产品天花板,实现 AI 芯片性能、功耗、面积、成本 (PPAC) 的最优平衡。
正如黄仁勋所讲,AI 需要一种基础设施,就像互联网、电力一样。如今,无论是 AI 工厂,还是 Agentic AI,或是物理 AI,所有这些场景都催生出强大计算能力需求,未来,数据中心将是新的计算单元。(本文首发于钛媒体 App,作者|林志佳,编辑|盖虹达)












