

最近,2025 年国际数学奥林匹克 (IMO)在澳大利亚落幕的两天内,AI 界因 「IMO 金牌认证」,开展了一场人才与技术话语权的双重争夺战。
OpenAI 抢先宣布其保密推理模型以 35 分达到金牌线,DeepMind 两天后也亮出 IMO 官方认证的同等成绩单。这标志着 AI 首次在 IMO 中比肩顶尖学生,实现从 2024 年银牌到 2025 年双金牌的数学推理能力跃升。
伴随技术进展而来的,是行业竞争 「好戏」:当 Demis Hassabis 公开谴责 OpenAI 提前泄露成绩时,媒体曝出 DeepMind 金牌团队三名核心研究员已被 Meta 挖角。
AI 数学能力的进步速度令人惊叹。但 IMO 金牌究竟意味着什么?这是数学界的 AlphaGo 时刻吗?AI 将会成为数学研究中值得信赖的合作者,还是沦为市场逻辑下的技术产品,消解数学的真正意义?
本周 《101 Weekly》 的第二期,我们邀请了 IMO 金牌得主,以亲历者的角度来聊聊两大 AI 的解题逻辑和数学水平,并透视竞赛背后的技术突破与数学的未来。
一、前后获得 IMO 金牌,DeepMind 与 OpenAI 之战
一觉醒来,我以为我穿越回高中了:朋友圈竟然有人提起 IMO(国际数学奥林匹克竞赛,International Mathematical Olympiad,面向高中生的国际性数学竞赛)。记得当年还是万里挑一的学霸才会去挑战这个比赛,最近却被 AI 拿下了:OpenAI 和谷歌 DeepMind 前后宣布他们的模型达到了 IMO 金牌的标准。
这个 「前后」 虽然只差两天,但却充满了戏剧性:今年的 IMO 是 7 月 20 日周日在澳大利亚闭幕,而 OpenAI 在周五,也就是 7 月 18 日晚上,就早早宣布了这个消息。
研究员 Alexander Wei 在 X 上说:OpenAI 最新的实验性推理大模型,实现了人工智能领域长期以来的一项重大挑战,在 IMO 竞赛的 6 道题目中解出了 5 道,并且最终获得了 35 分。IMO 的满分是 42 分,而 35 分恰好就达到了金牌的门槛。

两天之后,DeepMind 也下场宣布:Gemini Deep Think 的进阶版本模型也达到了这一成就。DeepMind 的模型在整个过程中完全使用自然语言操作,最后同样获得了 35 分的成绩,并且 IMO 官方组委会也证明了这一成绩。
IMO 主席 Gregor Dolinar 说:DeepMind 的解题在许多方面都令人惊叹,阅卷官认为这些解答清晰、严谨,而且大多数都很容易理解。
这个组委会亲自背书的待遇,却没有给到 OpenAI。Demis Hassabis 甚至特意下场,在 X 上表示:我们之所以没有周五公布,是因为我们尊重 IMO 组委会最初的请求。所有 AI 实验室都应该在官方成绩经过独立专家验证,并且参赛学生已经获得应有的表彰之后,才公开各自的结果。
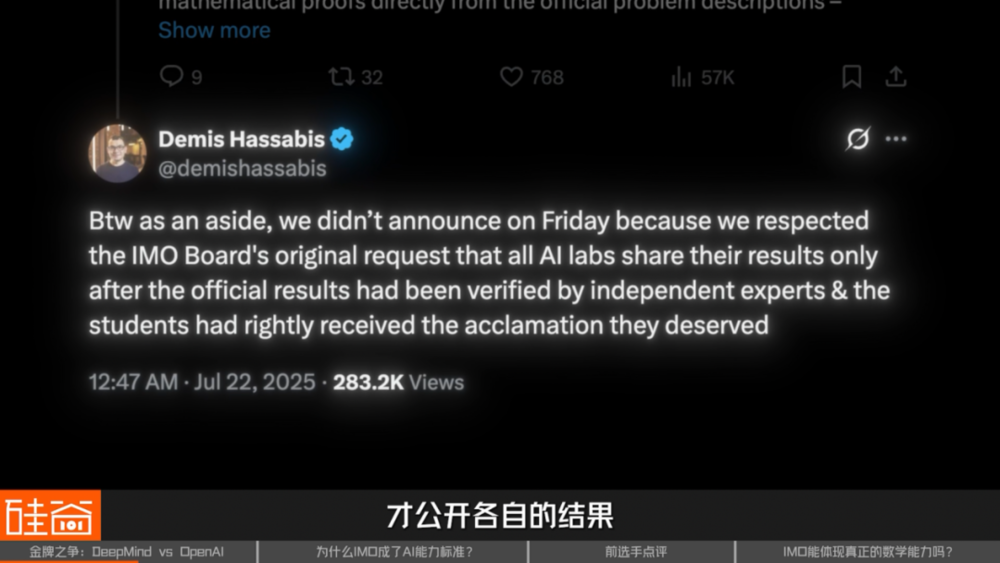
他还说:我们的模型是第一个获得官方 「金牌水平」 评级的 AI 系统——这简直就差点 OpenAI 的名了。OpenAI 之前的欢呼好像就没那么名正言顺了。
但更戏剧性的是,隔天媒体就爆出,DeepMind 这一金牌模型背后的研究团队中,有三名研究员已经被 Meta 挖走了。在此之前的六个月内,DeepMind 已经有 20 名员工被挖去了微软。
看来这场顶尖实验室之间的斗争,还在愈演愈烈。在吃瓜的同时,我们还是回到 IMO 竞赛这个话题上:AI 达到金牌水平,到底意味着什么?
首先要知道的是,这还远远说不上是数学领域的 AlphaGo 时刻。当年 AlphaGo 击败了世界围棋冠军李世石,震惊全球,最核心的原因是围棋被认为是人类智慧最难被机器超越的领域之一。
2022 年 DeepMind 的 AlphaFold 准确预测蛋白质结构,也被称为是生物学的 AlphaGo 时刻,我们硅谷 101 在去年的文章 《AI「入侵」 生物医疗史》 里详细解读了它的重要性。
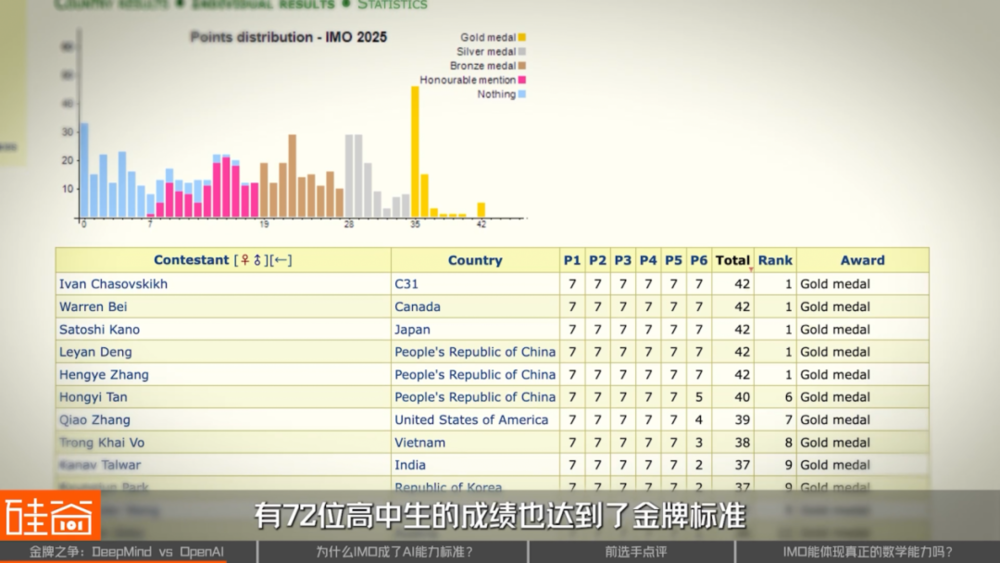
但是这次,有 72 位高中生的成绩也达到了金牌标准,其中 5 位获得了 42 分满分的成绩,也就是完美地解答了 6 道题,但两个 AI 模型都只做出来了 5 道。所以要说 AI 在数学能力上已经胜过人类,还为时过早。
但即使没有到 AlphaGo 的标准,IMO 金牌的结果也足够证明当下大模型优秀的数学能力了。纽约大学的计算机教授 Gary Marcus 和 Ernest Davis 就评价说:非常了不起。
二、作为能力标准的 IMO,证明了 AI 的数学推理能力
将解答 IMO 题目作为评估 AI 推理能力的标准,其实早有先例。
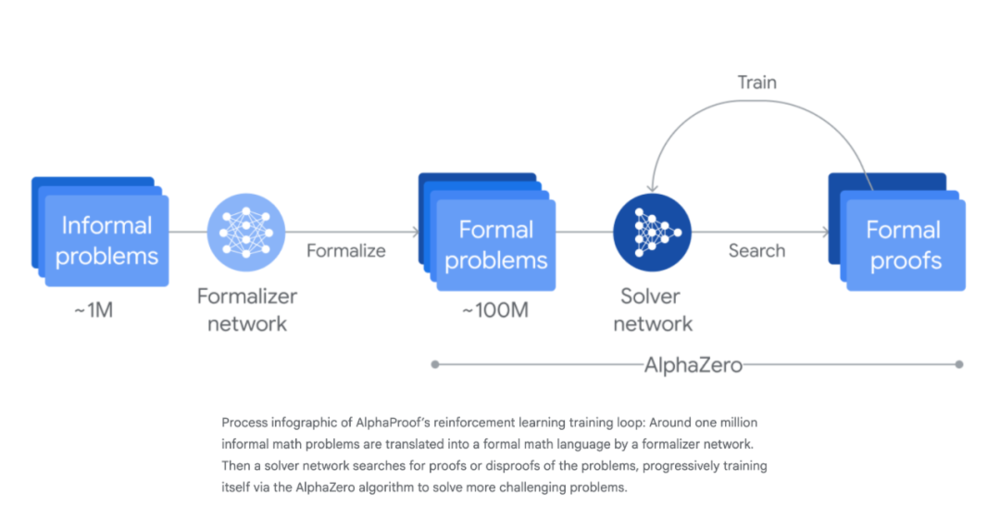
比如去年,DeepMind 发布了两个专为数学设计的模型:AlphaGeometry 和 AlphaProof。在 IMO 的六道题中,它们解出了四道,成为第一批达到银牌标准的 AI 系统。
图源:Google DeepMind
不过,这两个模型当时并不是用自然语言来解题,而是结合了 「形式化证明」 方法。简单来说,形式化证明 (Formal Proof)就是把数学问题转成机器能 「看懂」 的语言,再由 AI 用这种形式化语言一步步写出逻辑严谨、可验证的解答。
而这套语言的写作工具,就叫做 Lean(一种现代的定理证明助手和函数式编程语言,由微软研究院开发),类似编程语言。
为了让 AI 解题,研究者得先把自然语言题目 「翻译」 成 Lean,让 AI 去处理,再转回人类可读的答案。整个过程耗时长达三天——远超 IMO 给高中生两天、共 9 小时的比赛限制。
但这一次,DeepMind 最新的 Gemini Deep Think 模型在完全自然语言输入输出的条件下,达到了 IMO 的金牌标准。也就是说,AI 直接从自然语言读题、用自然语言作答——没有再依赖 Lean 或其他形式化工具。这背后的意义很重要。
一直以来,很多人都认为语言模型不具备真正的推理能力。比如问它:「strawberry 这个词里有几个 r?」,它可能就会开始 「内耗」,反复计算还出错。因为自然语言里没有明确的逻辑结构,推理过程也就不稳定。这也是为什么过去像 AlphaProof 那样的模型,需要把自然语言转成 Lean,绕开语言的不确定性。
但现在,DeepMind 证明了:语言模型本身,也可以完成高难度数学推理。虽然 DeepMind 和 OpenAI 都没有公开模型的具体训练过程,但和一年前相比,这确实是一次重大进展。
李元杉 (圣母大学逻辑学博士生):现在 AI 大家都知道是根据很多技术、从很多数据当中学习出来的一些参数,这样的一个结果,就不是说,我们预先给定了很多逻辑规则,然后它去执行。
同理,在数学上,最早期的用电脑来做数学的人会认为,把数学全部都形式化,然后运用这些规则,是解决数学问题的方法。但是现在,我们更多地看到这些公司会想办法把两者结合起来,甚至是直接使用语言模型去输出自然语言的数学,而完全不借助于形式化系统。
此前以 Gary Marcus 为代表的 AI 学者一直认为,语言模型无法独立完成真正的数学推理。在他的设想中,AI 模型必须依托像 Lean 这样的形式化语言,输出可以机器验证的逻辑结构,最后再人工转换成自然语言。也就是说,只有像 AlphaProof 这样的 「混合模型」 才有可能达到数学研究的标准。
因此,Gemini Deep Think 的成功,无疑在一定程度上挑战了 Gary Marcus 的观点。
李元杉:你可以看到 DeepMind 发布了自己的模型生成出来的解答,这个解答就完全是自然语言了,就没有一些代码之类的。但是相比于去年使用的那一套系统就是,它可能最终输出也是自然语言的,但是它需要先把这些东西翻译成一个逻辑语言,然后进行一些形式化的证明之后,再输出回来。
可能过往数学家会把用电脑辅助数学跟形式化方法等同起来,但是经过了这些语言模型的发展,以及它们证明了自己能够显示出一定的数学能力之后,他们可能会改变这个想法。
三、前 IMO 金牌得主点评,OpenAI 与 DeepMind 解题差异
为了让大家直观地对比 AI 和人类选手的解答,我们邀请了前 IMO 中国国家队成员胡苏麟,为我们分享他对 AI 回答的感受。
他告诉我们,AI 在作答的五道题中解答思路清晰、逻辑链条完整,获得满分是实至名归的。
但在具体题目里对比两个 AI 的回答,还是能发现一些有意思的情况。就比如第二题,一道平面几何题。

胡苏麟 (2019 年 IMO 金牌得主):
平面几何题对于 AI 来说,算是最容易做的题型之一了。在这里,两个 AI 也给出了不一样的做法。DeepMind 的做法是一个更加几何的,更加自然的做法,我觉得也是更接近于正常人类选手能想到的做法。相比起来,OpenAI 的方法就非常暴力,因为它直接使用了解析几何的手段。
用解析几何的办法,直接把这道几何题转化成了一道代数题,并且在它的解答过程中出现了巨量的计算。不过通常来说,人类选手通常不会在考场上做那么大量的计算。所以这个方法可能对 AI 来说,实行起来比人类选手要容易。
他还提到,两个 AI 作答时的语言风格也不同于人类选手。
胡苏麟:两个 AI 的一个共同点就是:解答过程中会不断引入新符号,来定义一些概念或者公式。这个选项在我上大学的高等数学的学习中比较经常出现,但在我以前的竞赛生涯中不太经常出现。原因是高中的竞赛题没有那么复杂,如果在解答过程中不断引入新的符号,反而会增加我们理解解答过程以及解答思路的难度。
两个 AI 的语言风格也有非常明显的区别。比如说 OpenAI 在它的解答过程中会经常出现一些人性化的描述词,比如 「XXX so far good」 或者 「XXX 我们完成了这一步」 或者 「nice」 之类的词汇。在一些方面也会适当省略一些细节,比如它会说 「很容易验证」 或者 「根据某某公式可以很容易检查下面这些东西是对的。」
所以总的来说,它给我的感觉像是一个在课堂上给学生讲题的老师,所以它会经常使用一些口语化的语言来鼓励学生,循循善诱,比如它会说 「我们已经完成了关键的一步,非常棒」,又比如 「我们已经完成了这个结论,真是一个漂亮的结论」 之类的话,来强调关键的步骤。

而相比之下,DeepMind 所用的语言则更加书面化,像是在阅读一篇数学论文。
四、AI 用于数学研究的前景,学术界褒贬不一
虽然和之前相比,大模型在 IMO 竞赛中的表现已经达到了质的飞跃。但我们的采访嘉宾告诉我们,IMO 终究只是数学能力的一个侧面:它是在一个限时、封闭的环境中,需要参赛者进行巧妙的思考,从而找到固定答案的一个竞赛。
这不是我们在生活中买菜逛街要用的数学,也不是数学家要穷尽一生思考的目标。
李元衫:
真正的数学研究,有时候目标可能更加开放,比如说,有些人可能会觉得自己做研究的目的是描述出一种现象,或者是发现一些具有规律性的结构。但是在你真正做出这些发现之前,你能发现出什么是不知道的。
所以说,相比于解决真正的开放性数学问题,可能解决竞赛问题对于这些模型来说,现在是更可及了。
在 AI 不断发展的过程中,数学学界也分裂成了两派:有人认为,AI 在数学和推理能力上的进展,已经能够在很大程度上帮助数学家。
比如澳籍华人数学家陶哲轩 (Terence Tao,菲尔兹奖得主,被誉为 「数学界的莫扎特」)就说:2023 年,AI 已经能够为职业数学家生成有启发性的提示和有前景的思路。当它与形式化证明及验证、搜索引擎、符号数学工具等结合使用时,2026 年的 AI 将会成为数学研究中值得信赖的合作者。
但与此同时,也有数学家对 AI 不那么信任。哥伦比亚大学的数学家 Michael Harris 就在自己的 Substack 博客中提出了对 AI 数学的批判。
他提出,数学的真正意义在于自由探索和内在洞见,而不是将其沦为市场逻辑下的技术产品。而像 Lean 这样的计算机语言,却将数学简化成机器能看得懂的逻辑,让他钟爱的数学失去了自由创造和思辨力。
同时,他十分关注数学研究资本化的趋势,担心类似 Google、NSA(美国国家安全局,National Security Agency)这样的资助者倾向于以应用价值衡量数学,而忽视其内在价值。
他批评当前关于 AI 辅助数学的讨论过分关注 「它管用吗」「会带来效益吗」,却忽略了 「对谁有益?」「为什么需要它?」 这类值得探讨的根本问题。
我们知道,李世石在被 AlphaGo 击败后选择提前退役。顶尖的数学家们会因为 AI 在数学上的成就,怀疑自己研究的意义吗?DeepMind 的 Pushmeet Kohli 在去年 AlphaProof 达到 IMO 银牌标准后就说,他认为这会促进数学学术研究。
Pushmeet Kohli DeepMind 科学家:
即使在围棋的例子中,我们看到的是,当围棋选手在比赛结束后开始分析 AlphaGo 的策略时,他们发现了很多以前没见过的关于围棋的新理论。而数学并不是一个游戏。AlphaProof 或类似的系统提供给你的,可以说是一个非常强大的工具,它可以帮助数学家和科学家们做一件大事:试图理解这个世界。
本文来自微信公众号:硅谷 101,作者:鲁漪文,编辑:陈茜