















GPT-5 上线次日,OpenAl 在一片用户的批评声中宣布向付费用户恢复 GPT-4o。
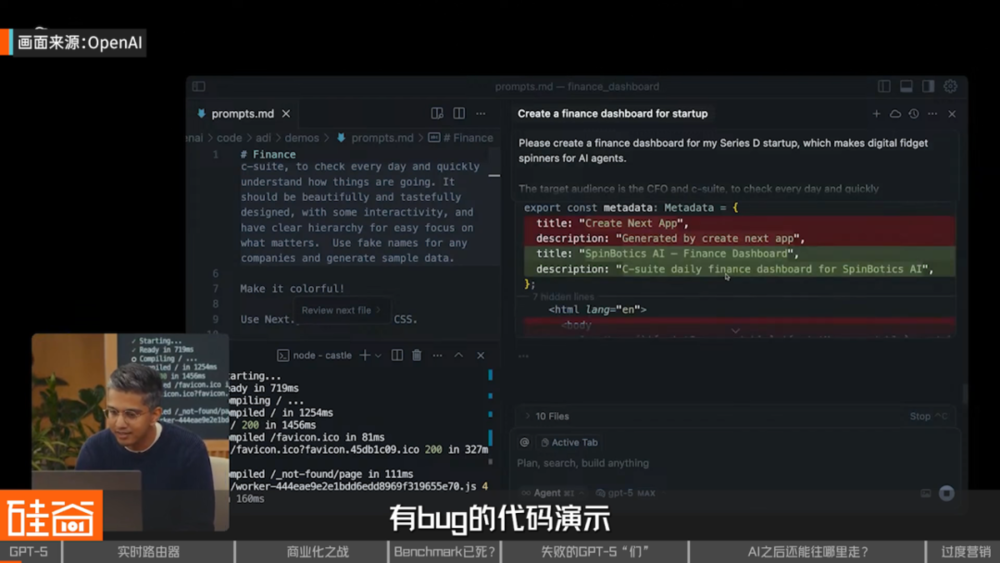
与 GPT-3 到 GPT-4 的惊艳跨越相比,GPT-5 的发布略显匆忙:翻车的数据图表、带 bug 的代码演示、误导的 「博士级」 科学原理解释,以及作为核心技术更新的 「Router」(路由器)也被硅谷 AI 从业者指出是已经存在好几年的技术。
从内部代号 Q-Star 到 Orion 项目的接连受挫,从数据匮乏到模型崩溃的技术困境,OpenAI 正面临前所未有的挑战。
但不可否认的是,作为一款产品,GPT-5 有着明显进步以及对用户交互的进一步优化。ChatGPT 正打入更多垂类领域,朝着 「AI 超级应用」 产品进发。而一场抢占市场份额、争夺企业订单的价格战,也在头部大模型公司之间正式开打。
本期文章,我们将深入聊聊 GPT-5 发布背后的技术困境、商业焦虑与未来趋势。
OpenAI 为什么引发外界这么多的吐槽?GPT-5 的开发过程遇到了哪些技术瓶颈,最终选择了什么架构来攻克?作为产品的 ChatGPT,为什么选择进军教育、健康医疗和编程市场?
而更令人担忧的是,AI scaling law 已经碰壁,强化学习、多模态能力和新架构范式能否为 AI 发展指明新的方向?
一、GPT-5 发布会漏洞百出,突破放缓
说实话,外界对 GPT-5 的发布非常期待。原因很简单:GPT-4 发布已经是两年半之前的事情了,而外界已经等新一代模型很久了。
但总结来说,GPT-3 到 GPT-4 的能力跨越太过惊艳——所谓的 「ChatGPT Moment」。
这样的 「Wow moment」(惊艳时刻)是这一轮生成式 AI 技术革命的基础,但 GPT-4 到 GPT-5 的能力跨越,却远没有达到外界的期待。

朱哲清 (前 Meta AI 应用强化学习负责人,Pokee AI 创始人兼 CEO):
你要横向对比,就是 GPT4 和当年 GPT3 的对比,这个的是天和地的区别,对吧?GPT4 跟 GP5 如果你是以同样的标准来做对比的话,其实差距是没有那么大的。就是它可能是一个在我看来是个改进,而不是一个阶段性变化。
GPT-5 发布了什么呢?
Chapter 1.1 业内推测 GPT-5 技术路线
首先,此前新闻爆料,GPT-5 会成为一个 「统一大模型」(unifying system),能强大地将推理、编码、语音、研究等能力整合进单一模型,实现 「既要」 和 「又要」 的用户需求,将 GPT 系列和 o 系列的模型融合,这个单一模态架构能自动调取相应的模型和能力,而不需要用户之后自己选择模型了。
虽然 OpenAI 目前还没有正式发布详细的 GPT-5 技术报告,但业内的技术专家们猜测,这其实不是一个端到端的超级大模型,而是由一个实时的 「路由器」(Real-time Model Router)来 「拼接」 下面的不同子模型。
其实这个技术路线,不是创新也不是突破,早在硅谷初创技术圈里就存在很久了。

Aiden He(TensorOpera AI 联合创始人):
GPT-5 就是一个典型的联合的系统,它是把已有的 GPT-4,o3 等推理和非推理的模型串联到一起。
它可能是因为商业化比较着急吧,我觉得更应该把它叫做 GPT 4.99,因为它是在所有的历史上的一个聚合方案。这个路由器,其实并不是一个很新的东西。
这种路由器的方案主要是一些初创公司在使用,大概有三个使用场景和原因:
第一,是在手机这样的设备端上,有端上的小模型,也有云端的大模型,简单的问题用本地模型,复杂的问题用云端模型,就需要有个路由器去帮你做选择。
第二,是初创公司们做模型层之上的开发和应用的时候,把所有开源和闭源模型聚合起来,把不同的任务给不同的模型来调用。
第三,是要去平衡系统的成本,比如说用户的一些高频又简单的提问,像 「hello」 和 「thank you」 这种 query(查询)量非常大,光是这种简单的问题每天都在消耗 OpenAI 上百万美元的费用,所以这些典型问题都可以直接分发给非常小的模型去解决。
所以,这些是之前初创企业们因为要平衡系统成本,开发和应用时的主要三大使用场景,但如今被 GPT-5 作为主打技术突破,让外界不少人怀疑,一个端到端训练的超级大模型路线已经触顶。
而 OpenAI 不得不开始用这些 「取巧」 的技术来解决 「产品层面」 的问题,而不是 AI 大模型 「智能飞跃」 的问题,这是和外界的期待非常相悖的。
当然,实时路由器也没有那么好做,整合各种多模态也有很多技术上的挑战,这也可能是发布推迟的原因之一。
Aiden He(TensorOpera AI 联合创始人):
有的模型擅长于数学,有的模型擅长于写作,有的模型擅长于编码,所以你要根据用户的意图、语言类型、各种各样的地域位置,包括它的语言偏好去分发模型,这是一个非常复杂的问题。
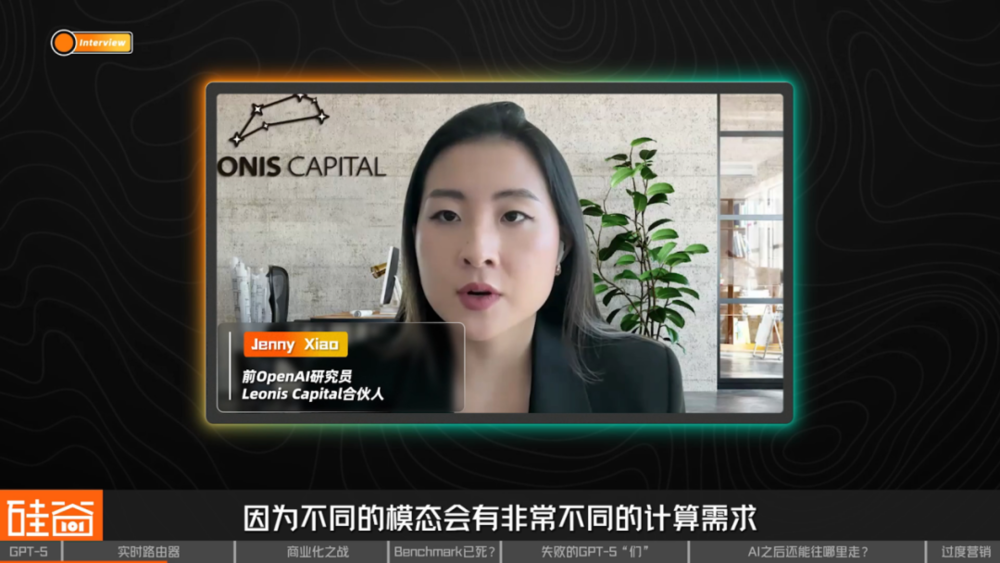
Jenny Xiao(前 OpenAI 研究员,Leonis Capital 合伙人):
不同的模态会有非常不同的计算需求,以及许多不同的推理需求。例如,如果是语音模块,它就会需要非常低的延时。因为如果延迟太大,你和 AI 进行对话时就会变得很尴尬。而其他模块,比如深度推理或研究,可能会有两三分钟的延时,甚至更长,有时候我觉得都有 30 分钟。所以把所有这些模态整合在一起,还要确保产品不卡顿,这是一个相当大的技术挑战。
抛开这不是一个多么酷炫的技术不谈,说实话,单从用户角度来看,我本来觉得这点改进还挺好的。
因为之前的 ChatGPT 确实像个大杂烩:4o,o3,o4-mini,o4-mini-high,GPT-4.5,GPT-4.1,GPT-4.1-mini,旁边还有 Codex,视频模型 Sora,已经 agent 生态的 GPTs……简直太乱了。
所以,如果 GPT-5 能自动为我挑选最适合的模型,其实在用户交互上是挺重要的。
但这里的关键词是:你得能选对,且效果得比之前好。
然而,当 OpenAI 取消此前自选模式,在社交媒体上用户们却开始集体抗议,很多人认为 GPT-5 没有 4o 的亲切感,效果甚至不如 4o,并且用户有种被剥夺了选择权的感受,所以在 X 上,非常多用户集体呼吁 「让 4o 回来,不然就注销 ChatGPT 账号。」

这也让 OpenAI CEO Sam Altman 不得不在周末之前回应,保证将上线更多定制化的功能和内容,并持续对 GPT-5 进行改进。
OpenAI 在这次发布会中,一直在强调要给用户的不是 「more information」「越多的信息不一定是越好的」,而是要给 「just right」 的信息,「刚刚好的、适合」 的信息。
这个出发点看起来没有什么问题,但在技术上,怎么去定义 「just right」,什么是 「刚刚好」,还蛮有争议的。关于 GPT-5 的优化,我们也会继续关注。
接下来,我们再聊聊这次发布会上,OpenAI 展示的三个应用场景:教育,健康医疗以及编程。
毫无疑问,这将是 OpenAI 进军商业化的主要三个战场。
Chapter 1.2 三大垂直应用场景
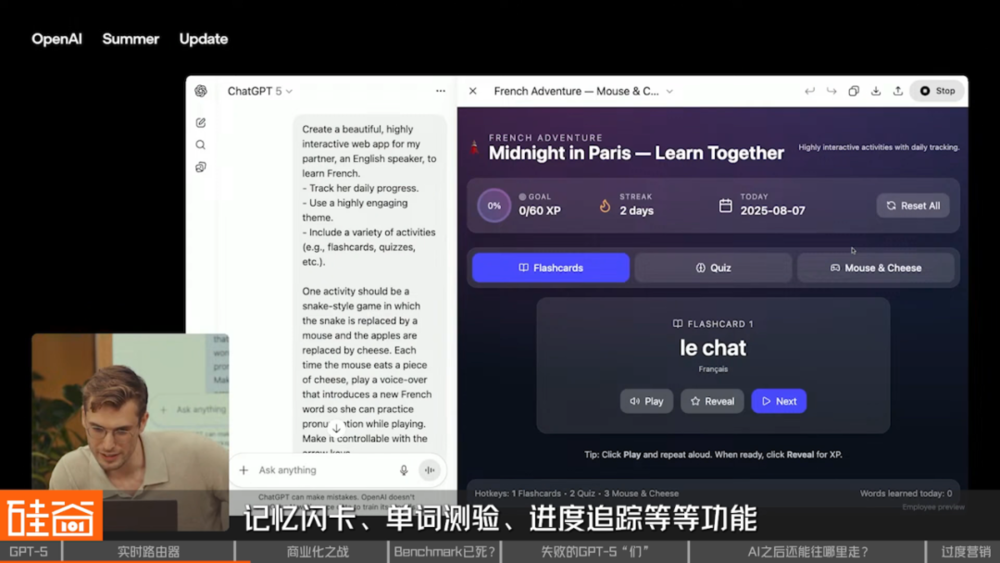
在发布会上,OpenAI 展示了用多模态学习韩语的场景,效果确实看上去挺丝滑的:语音模型进一步升级,可以实时加快放慢,感觉会是非常好的教育交互场景。
GPT-5 的玩法更加升级。你还可以让 ChatGPT 直接给你做个学法语的网页,或者小游戏应用,几分钟时间,记忆闪卡、单词测验、进度追踪等等功能应有尽有。
所以我们看到语言学习公司多邻国股价在 GPT-5 发布会期间就开始大幅度震荡,本来因为财报非常好出现盘中大涨,但 OpenAI 发布会之后开始一路狂跌,也是市场在质疑,ChatGPT 在之后会抢夺多少教育市场的份额。
Jenny Xiao(前 OpenAI 研究员,Leonis Capital 合伙人):
我认为教育是 OpenAI 非常明确的一个垂直领域。ChatGPT 刚推出时,基本上把 Chegg 给 「干掉」 了。Chegg 是一家教育公司,学生主要用它从同伴那里抄作业。ChatGPT 推出后,学生们就觉得,我们好像不再需要 Chegg 了。如果你看 OpenAI 模型在 2023 年初的早期用户,你会发现很多都是学生,而且在暑假期间,OpenAI 的使用量会大幅下降。接着,OpenAI 最近推出了 「学习」 功能,我觉得这个功能更多是针对那些想随便学学或者是探索某个主题的人。
就语言学习而言,我一直在用 ChatGPT 练习粤语,我感觉它效果非常好。我以前是用多邻国,但我觉得 OpenAI 比多邻国自由度高得多,因为你可以用 OpenAI 探索任何话题。我认为 OpenAI 肯定会去切入这些 (语言学习)公司的营收领域,因为在 ChatGPT 的原生环境下,复刻它们的模式实在太容易了。
另外,OpenAI 强调的市场蛋糕还有健康医疗领域。因为 GPT-5 号称有着博士级别的能力,所以在医疗健康领域,也能够对专业的癌症诊断报告做通俗易懂的解读。
在发布会中,OpenAI 请到一名女性癌症患者,她分享到说,去年被诊断出癌症病情,收到的报告有许多医学术语,她让 ChatGPT 先帮助她厘清资讯,并与医生的评估进行比对,再做出关键决策。
而她也形容说,GPT-5 更快速、更完整,在整个治疗过程中,让她觉得有了一个 「伙伴」。

这一点我也感触蛮深的。医疗领域是一个医生和患者知识差距巨大的行业,因为这样的知识差距,导致了两者关系的不平衡,患者通常没有选择。
我最近身边有个好朋友进了重症监护室,陷入昏迷整整五天,她家人刚开始除了每天去医院求医生,感觉什么都做不了,但很快用上了 AI,开始对病情和治疗方案各种学习和讨论,之后感觉和医生交流的时候障碍变小了很多,在做出一些关键决策的时候也心里更有底了。
我觉得这就是技术的光明面:赋予人们自主权。
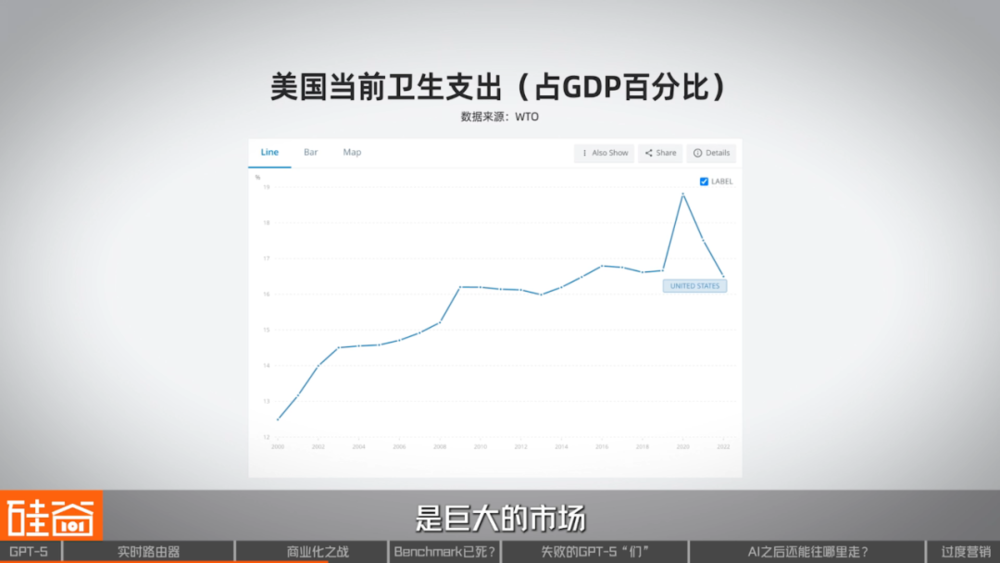
而健康医疗行业占据美国 GDP 的 18% 左右,是巨大的市场,OpenAI 不会放过这个市场。
同时,我们看到全球 AI 医疗市场也在井喷式发展。市场预测,全球 AI 医疗领域规模会从 2024 年的 26.69 亿美元飙升至 2030 年的 188.38 亿美元,年复合增长率高达 38.62%。
包括 OpenAI 参与投资的、专注于利用 AI 减轻医疗专业人员行政负担的初创公司 Ambience Healthcare 最近 C 轮融资 2.43 亿美元,迈进独角兽行列。所以我们接下来会看到 OpenAI 在医疗健康领域的进一步动作。
另外一个 GPT-5 要打的核心商业战争,就是编程市场了。
无论是低提示词的非专业用户场景,还是专业编程场景,都展现出代码能力的强势升级。
同时,OpenAI 来请到了最炙手可热的 AI 编程初创公司 Cursor CEO 到现场分享如何用 GPT-5 打造出最高效的编程体验。
这里能看出,自从 Anthropic 开启了 Claude Code 产品之后,AI coding 初创公司就开始纷纷站队了。
之前 OpenAI 本来想买 Windsurf 没买成,我们之前也出了视频跟大家讲了这个狗血的收购大瓜,现在 Cursor 明显站队 OpenAI 一起来打 Claude,这是一轮新的编程市场争夺战。
Aiden He(TensorOpera AI 联合创始人):Anthropic 其实做了很多很多事情,它在开发者社区的影响力,我觉得会大于 GPT-5;GPT-5 可能大家会做应用,各种东西 PoC(Proof of Concept,概念验证) 快速起步,但是一些专业的开发者可能还是比较喜欢 Anthropic,所以它一定是各有所长。但就算是 OpenAI 主打及自夸 「世界最强」 的编程场景,其实也让很多人失望。
朱哲清 (前 Meta AI 应用强化学习负责人,Pokee AI 创始人兼 CEO):
我可能本来的预期可能在于,比如说在代码领域,它单一模型可以直接端到端,从架构到写每一个前端、后端代码,到它知道选择什么工具,到我怎么把这些东西都串联起来,然后自行测试。完成测试以后,可能回过头来再去改自己的代码,类似于有这样的一个端到端的能力。
从 OpenAI 的定义上面,能超越它第三阶段 agentic experience(智能体体验,模型以智能体身份主动行动)定义,再往上走一点那种感觉。但目前看起来完全没有。总体在我看来,是跟 Anthropic 的 Claude Opus 差不多的能力范围。

Chapter 1.3 错误百出的发布会
同时,这场发布会不得不吐槽的,就是现场出的各种 bug 了,让这场万众期待的发布会显得特别 「草台班子」。
这个时候,OpenAI 得感谢自己还没有上市,如果是谷歌的发布会出现这么多错误,可能股价早就蒸发上千亿美元了。
首先在发布会直播中,一张展示 GPT-5 在编程基准测试 (SWE-bench)上性能的图表出现了严重错误,图上,代表 GPT-5(52.8% 准确率)的柱状图,其高度竟明显超过了代表旧模型 o3(69.1% 准确率)的柱状图。
另一款模型 4o 的柱状图与 o3 的水平位置一模一样,标注的数字却是 30.8%。这个错误低级到不敢让人相信是 OpenAI 的发布会。

尽管 OpenAI 事后在官网上修正了图,Sam Altman 也发文自嘲了,但这个图的火爆和出圈程度直接秒杀 Sam Altman 之前铺垫的任何营销努力。
而更严重的是,这显示出的不仅仅是匆忙和粗心,更是 OpenAI 团队试图在数据呈现上营造出的 「巨大进步」 的假象。
同时,Benchmark「分数打榜」 这件事,也正变得更越来越不重要。
朱哲清 (前 Meta AI 应用强化学习负责人,Pokee AI 创始人兼 CEO):
前两天 OpenAI 刚 release(发布)的 open-source model(开源模型),它在 Benchmark(基准测试)上面的 performance(表现)也还可以,但是它真正使用起来,它的代码能力其实挺拉胯的,它出现了很多的 bug,很多代码都跑不通。
Jenny Xiao(前 OpenAI 研究员,Leonis Capital 合伙人):
基准测试 「已死」,但新形态的 「基准测试」 又会死灰复燃,对吧?所有这些实验室都非常注重在基准测试表现上的提升。他们会为了在某个特定基准上提升 3% 或 5% 而相互竞争,而且很多研究人员也以模型在这些基准上的表现为傲。但作为用户,我的感受是,基准测试对用户来说毫无意义。所以我认为,下一个竞争前沿会主要转向用户体验。我觉得现在,很难靠原始性能来区分模型的优劣。
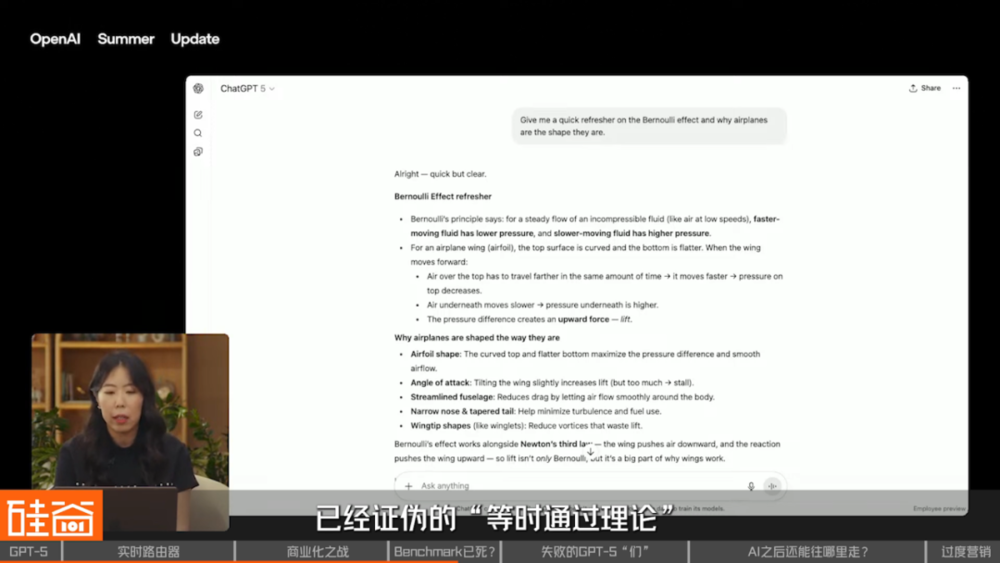
另外还有一个尴尬的细节:在演示过程中,GPT-5 在解释 「伯努利效应」 时,错误地采用被主流物理学教材已经证伪的 「等时通过理论」。
前一秒 Sam Altman 还在说,GPT-5 是属于 「博士级别」 的 AI,后一秒就直接自己打脸,还挺尴尬的。
这显示出,GPT-5 完全没能识别过时的错误解释理论,让外界对这个新模型的理解和推理能力有了更多的质疑。
不过有一说一,在解释这个理论时自动产出高质量 SVG 动画与可交互代码还真的挺酷炫的 (感觉对我们的视频后期之后会非常有用),也说明 OpenAI 的多模态生成能力确实还是很强的。

朱哲清 (前 Meta AI 应用强化学习负责人,Pokee AI 创始人兼 CEO):
我的总体感觉是,OpenAI 在尝试在那么多个模型发布之后,想要在这个阶段上站住脚跟,把自己这个领先地位占住,所以它必须要去做这么一个发布。
大概总结一下 GPT-5 发布的重点:GPT-5 解决的都是产品层面的问题,并没有技术颠覆性的创新,这说明接下来一线大模型的技术差距也会进一步缩小,大家都用着差不多的方式在把模型能力艰难地往前推,不过就是:堆算力+堆数据+高质量数据筛选+后训练+推理时长+工具使用。
因此,我也看到一句话说 OpenAI 从 「The One」 变成了 「One」,从 「引领者」 变成了前沿模型 「之一」。
为什么 GPT-5 会这么拉胯?是不是 LLM 的发展路径真的已经碰壁了?
二、失败的 「GPT-5 们」Transformer 架构的发展瓶颈
GPT-5 的训练从很早就开始了,但非常有意思的是,没有一个模型在 OpenAI 从第一天就被命名为 GPT-5 的。
Jenny Xiao(前 OpenAI 研究员,Leonis Capital 合伙人):
我们都清楚,OpenAI 一直在训练下一代模型,但肯定只有在达到一个重要的里程碑后,他们才会给模型正式命名。GPT-5 自 2024 年以来一直在训练,但只有到达一个重大节点之后,OpenAI 才会将这个模型命名为 GPT-5。
OpenAI 在推出 GPT-4 的时候,所谓的 「下一代大模型」 就已经在训练当中了,但如果这个模型不够好,不够 「wow」 到大家,那它就注定不能被叫做 「GPT-5」。
比如说,在 2023 年年底就被曝出 OpenAI 内部代号为 「Q Star」 或者 「Project Q」 的项目,但这个模型后来被称为 「o1」。
Jenny Xiao(前 OpenAI 研究员,Leonis Capital 合伙人):
OpenAI 在另外一个叫 Project Q 的项目上投入了很多精力,很多人也叫它 Q star。这个项目在 2023 年 11 月左右,也就是 Sam Altman 那场风波期间被泄露了出来,最终成为了 o1 系列,也就是 o 系列。这个项目非常重视思维链推理,想要打造推理模型。这个就是所谓的 Q 项目。

其实 「O」 系列模型还算成功,后来又更新了 o3 和 o4-mini,但依然不能被称为 GPT-5。为什么呢?
The Information 在 GPT-5 发布之前出了一篇非常重磅的文章,爆料了 OpenAI 内部的这几次关键的 GPT-5 研发挫败。
其中在谈到 o 系列的时候说,这样的推理模型似乎帮助 OpenAI 克服了预训练阶段性能增长放缓的问题,而且 2024 年年底的 o3 母模型 (也称为教师模型)在理解各种科学领域及其他领域方面,相比 o1 的母模型取得了显著的进步,当然这个进步也是因为 OpenAI 用上了更强的英伟达芯片服务器。
但奇怪的事情发生了,当 OpenAI 将 o3 母模型转换为能让人们提问的 ChatGPT 版本 (也称为学生模型)时,效果出现了显著下降,甚至比 o1 表现好不了多少,同样的效果下降也出现在了 API 的模型版本中。
业界有猜测是因为基于人类自然语言的聊天产品形态拉低了模型的能力水平,限制了 AI 的发挥。

Nathan Wang(硅谷 101 特约研究员,资深 AI Agent 开发者):
可以理解说大模型是理解高维度复杂内容的,但是最终它要跟我们人类交流,或者是要把它转换成人类理解的文字的时候,它需要通过这样降维的方式。就相当于一个高等的生物需要降维,才能跟我们人类进行交流。在这个降维这个过程中,其实它会损失很多高维度的信息。
包括我们自己其实也有一些各式各样的潜意识层面或者高维度的思考。最终我们要个人表达的时候,是要通过语言,但是语言其实并不一定真正能够把我们大脑中的所思所想,全部都很清晰地表达出来,或者甚至说,有些东西是没有办法去表达的。所以从这一点上来看,当你去需要这个模型通过语言来跟人交流的时候,在一定程度上拉低了模型自身智能的表现。
除此之外,在 o3 之后,OpenAI 内部有一个代号为 「Orion」 的项目,在今年 2 月份推出,但也没有掀起什么水花,估计 OpenAI 对它的信心也不大,所以也没有把 GPT-5 的名字给它,而是叫了 「GPT-4.5」。
Jenny Xiao(前 OpenAI 研究员,Leonis Capital 合伙人):
我个人认为最大的挑战仍然在于预训练,因为早在去年年底,甚至更早的时候,scaling law 就已经碰壁,因为我们正在耗尽高质量且多样化的人类生成的数据。缺乏数据是 OpenAI 的 Orion 项目延期的最大因素。
有些人会称这个项目失败了,有些人则会说是延期。但本质上,在 OpenAI 训练 Orion 系列模型时,他们就已经遇到了缺乏高质量、多样化数据的问题。他们最终是用由 OpenAI 的 o1 模型生成的合成数据来训练 Orion 系列,但结果仍然没有达到人们的预期。
我觉得 OpenAI 4.5(也就是 Orion 模型)会没那么成功,是因为它真的没有带来让人眼前一亮的突破。就好比几乎没有人特别关注 4.5 版本。
同时,The Information 的报道中说,2024 年下半年,Orion 没能成功的部分原因在于其预训练阶段的局限性。
同时,OpenAI 还发现对 Orion 模型做的优化在模型较小的时候有效,但当模型规模增大时,这些优化就不再有效了——模型训练的不确定性仍然非常大,有很多的因素会导致模型训练的失败。
之前在硅谷 101 的播客录制中,我们的嘉宾 Bill Zhu 也跟我们分享了训练模型中会出现很多模型崩溃的情况,甚至可能会在强化学习过程中出现所谓的 「灾难性遗忘」。
朱哲清 (前 Meta AI 应用强化学习负责人,Pokee AI 创始人兼 CEO):
你是不可以无限制训练模型本身的,就是你训练到某一个程度它就会 fall apart(崩溃)。其实在 RL 领域之前很经常看到叫 catastrophic forgetting(灾难性遗忘)——在你训练很久很久以后,它开始忘记所有过往学到的知识,然后整个模型像疯了一样,所有原来的 policy(决策策略)都消失。
这是为什么你一开始模型要变得足够大,其实就像海绵一样,然后你往里面不停地注水,然后你注水注到一定程度它满了,那你再往里面注水,就会流出来一些,但流出来的不一定是注入的水,很有可能是原来已经有的一部分水,甚至是很重要的水。
就像你大脑里面不停地灌输知识,然后最后过载了,把加减乘除忘了,那剩下的所有知识体系就直接 fall apart(崩溃)。这个问题本身叫 model plasticity(模型可塑性),就是说它的可塑性到了某种程度就直接崩溃了,然后你要怎么去解决这个问题?
叫 Continual Learning(持续学习),现在可能你有一天会人类生成一个 terabyte of data(1TB 的数据),那 10 天是 10 个 terabyte(TB),那未来可能生成数据还会越来越多,那你怎么能够用一个模型无限地去训练它,让它仍然能够对未来的知识进行获取?这是不可能的。
这样看来,以 Transformer 架构为基础的 LLM 模型发展,如今确实可能到了一个关键的时刻,或者需要一个完全不同的新架构来突破技术壁垒。
三、未来 AI 进化路径,强化学习、多模态、JEPA
接下来前沿的大模型该如何继续优化呢?我们跟身边的技术大牛聊了一圈,总结了三种方式:第一是强化学习,第二押注多模态能力提升带来的突破,而第三,是寻找其它的框架范式。
首先是强化学习路线 (Reinforcement learning),简称 RL,包括 RL 在预训练阶段的尝试。
朱哲清 (前 Meta AI 应用强化学习负责人,Pokee AI 创始人兼 CEO):
我先讲讲以 RL 为核心的训练机制为了解决什么问题。很多的任务是以目标驱动的,比如说写代码,比如说数学、物理、金融机构的一些东西,再比如城市规划,你做 Operations research(运筹学)、供应链这些东西它都是有明确目标的,世界机制也很完整。如果 A 发生了会出现 B。在这种情况下,Pre-training(预训练)就变得不是很有必要。
这种专业型的目标为驱动的场景,大多数都是没有任何的数据的。数学跟代码是仅有的两个可能数据点相对多的场景。除此以外,我刚刚说的剩下的那些点基本上都没什么数据,你很难在互联网上得到大量的数据去完成训练。
本质上它要解决的问题是非常泛化的,而市面上已经出现的数据,大多数都聚焦在一些经常会发生的代码问题和数学问题。而那些非常高深难测的数学问题,它是从来没有出现过的,它必须要通过一个反事实的形式,就是我要生成一些市面上从来没有出现过的代码、数学、物理规划等等的输出。
然后靠一个 ground truth(真实标签)的 validator(验证器)来告诉我做得对不对,然后去 self-train(自我训练)。这种训练方式是非常适合于这种有真实标签、能够做出精确判断的这种用例,然后去进行优化。
这是 RL 最闪光的时候了,其实有很多研究在网上都说过,其实现在最大的问题是验证,我如果能够找到一个好的 verifier(验证器),我可以认为问题解决了。因为可以通过 RL 去完成对于这个验证器的优化就可以了。
Bill 说的 「验证」 是 RL 中非常重要的关键,也是 The Information 爆料中,GPT-5 在 RL 上的杀手锏。
报道说,OpenAI 一直在开发一个被称为 「universal verifier」(通用验证器)的技术:让一个大语言模型使用各种来源的研究,来检查和评估另一个模型的答案。它可以自动执行,确保模型在强化学习过程中生成高质量答案。
朱哲清 (前 Meta AI 应用强化学习负责人,Pokee AI 创始人兼 CEO):
这个方向就像我们当年看到 Alpha Zero 打败人类一样,它所能够走出的一些路子是人类正常想象不到的。通过这个机制,甚至可以发现新的物理定理,它可能可以真正去发现人类所不拥有的知识,这可能是下一步我觉得真正迈向 super intelligence(超级智能)的一个关键点,但目前还没有很好的一个突破。
而接下来,需要各大模型公司去探索的第二条路,就是多模态。
就像前面我们说到的,大语言模型的维度是非常有限的,而多模态,以及世界模型将对接下来 AI 的发展至关重要。
Aiden He(TensorOpera AI 联合创始人):
我们要注意多模态,因为多模态一旦引入,它就有非常复杂的工作流,比如说你要用浏览器,你要用数学,你要用代码,你要使用各种复杂的工具。然后包括多模态的使用,比如说,你看 GAIA(Generalized AI Agent benchmark,一种面向生成式 AI 的基准测试)提出来的框架,它其实是非常复杂的任务,人类去完成都可能要 6-15 分钟,如果 AI 不断地把时间降到 6 分钟以下,我觉得这也是学术界、创业公司一直在追求的。比如说我们在金融领域去做很复杂的自动交易策略,包括给网红们去做发帖,其实这里面有非常复杂的步骤。
你怎么把它的 boundary(能力上限)提高。我觉得两个层面,一个是在应用这样的 multi-agent(多智能体)系统,不断去推高需求;另外一个是在某些能力层面,大家不断地去螺旋式上升,自己训更大的 model(模型),当模型因为算力和能源限制的时候,它就会去做 multi-model(多模型)的组合。
所以上面是多智能体,下面是多模型,我觉得这个是接下来我比较看好的两到三年的一个发展路线图。

朱哲清 (前 Meta AI 应用强化学习负责人,Pokee AI 创始人兼 CEO):
对于大方向的突破,我感觉应该肯定会发力在多模态上面,特别是在视频跟 world model(世界模型)上面。因为人类的语言本身是一个非常大的 compression(压缩包),它的信息搭载量和视频的信息是一个数量级的差异,这件事情我同意 Yann LeCun 的说法,人类从视觉、听觉、触觉各方面的多维度信息采取、吸收量,是要比纯文字要高出大几个数量级的。
文字训练的一个假设是:我如果能够通过一些简单规则,比如 reinforcement(强化学习),fine tuning(微调)或者 reward model(奖励模型),通过一个简单规则或者简单的判断方式,或者训练出来、或者写出来的判断方式,能够去判断一个模型的好坏、告诉你怎么去提升这个模型。
它就相当于一个文字领域的 world model(世界模型)。比较复杂的点是,当出现了多模态视频,可以 navigate environment(导航环境)之后,它的评估难度就会高很多。从纯 pixel(像素)的方式去做评估,这个是目前机器人技术领域肯定没有解决的问题。
如果 world model(世界模型)能有大幅度提升的话,我们有一个很大的机会能够去训练,比如说视频理解的模型、机器人技术的基础模型、游戏的基础模型,这些基础模型的诞生再给到一个机会,让我们去后面再去做 post-training(后训练),它可以在整个多模态的世界里面创造 text-based model(基于文字的模型)的一个同样的可以复制的成就。
然而在那些领域当中,它所代表的市场份额,或者整个市场的空间,其实比纯文字的市场空间要更大。它可以把一个纯文字交流式的非常压缩信息的系统拓展成一个,或者是线上的非常丰富的信息,或者说视觉、听觉、触觉的一部分,或者直接线下的机器人技术的东西,它们的能够部署的这个领域有一个非常大的延展,所以我觉得我刚刚说的像世界模型这个方向,视觉的方向,一定是下一步最重要发力的方向。

而多模态之战确实在最近变得非常激烈,谷歌最近发布世界模型 Genie 3,这在一些业内人士看来,重要性是要超过 GPT-5 的。
此外,Bill 提到的图灵奖得主 Yann LeCun 近年来提出的核心研究方向叫做 Joint Embedding Predictive Architecture,简称 JEPA,翻译过来是 「联合嵌入预测架构」,旨在克服大语言模型的局限,推动 AI 理解物理世界。

Nathan Wang(硅谷 101 特约研究员,资深 AI Agent 开发者):
JEPA 本身它是把所有模型的训练放到 Latent(潜层)空间中去完成。它在潜层空间的话,对于你的输入是有一个抽象的表达,对于你的输出也是一个抽象表达,这样你就可以再把输入、输出都同时放到这样的一个维度空间中训练。
然后再给到它不同状态的量,让它可以在潜层空间中去预测 「我下一个动作应该是怎么样的」 或者 「我下一个应该预测的,是怎样的一个状态?」 它在这个过程中就不是一帧或一个一个像素去预测的,而是把你遮挡了的某一块可以整体地给预测出来。
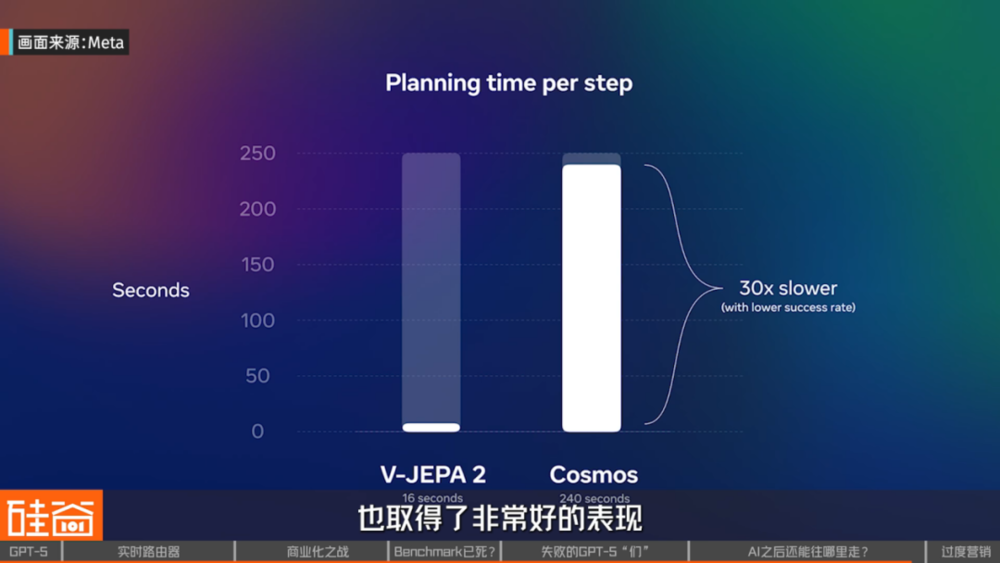
JEPA 本身其实也分 I-JEPA(image 图像 JEPA)和 V-JEPA(video 视频 JEPA)。最新发表这个文章其实也表现出,在预测整个视频中的事物变化时,也取得了非常好的表现。所以,我个人比较看好一些非 transformer 的架构,是否在未来可以给我们一个真正的智能,更加接近或模拟我们人脑思考的一个方式。
我觉得 transformer 的局限性是存在的,但我们也有其他架构作为替代方案,也有不同的团队在进行探索。所以大家可能也需要去关注一些非 transformer 方面的模型究竟是怎么样去模拟人类的智能。
四、GPT-5 被过度营销反噬,但 AI 进化不会停止
最后还想说,这次 GPT-5 的翻车与 Sam Altman 之前过于浮夸的营销分不开。
在发布会之前,他在 X 上的各种预热还有用词,一会儿在他弟弟的播客上感叹自己 「相对于 AI 毫无用处」,一会儿又在 X 上晒出与 GPT-5 的聊天截图,各种 「暗示」,但又保持神秘,吊足了公众的胃口,把期待值拉得太高。
结果发布会出来,大家都愣了。所以,这次发布会的失利也是被视为 「营销鬼才」 的 Sam Altman 太过度营销的一次反噬。
总结一下,长期来看,到达 AGI 之前,我们可能还有很多工作要做,还有很多技术壁垒需要突破,而这些突破需要脚踏实地的研发和创新。
但很遗憾的是,在人类的技术进一步被推进之际,OpenAI 等大模型公司却开始在商业化上变得非常激进,包括发布 GPT-5 之际正式开始打价格战,来圈地、圈市场份额。
这让不少人担心,会不会这次的 GPT-5 发布会意味着 AI 泡沫破灭的开始?AI 大模型的进展是否会就此停止呢?
Nathan Wang(硅谷 101 特约研究员,资深 AI Agent 开发者):
所以我个人也是比较期待类似像 JEPA 这样的一些新的构架能够出现,有更多人能进行探索,而不是因为 transformer 现在可以给我们带来很多经济利益、经济价值,就只是停留在这个阶段,然后一直所有人都寄希望于 scaling law 能够继续持续下去。
从 GPT 5 的发布来讲,我觉得大家也可以更好地去清醒地认识到 transformer 本身的局限,可能也有更多人可以去关注其他的一些替代方案,能够帮助整个 AI 行业得到更深远的发展。
最后,虽然我们这个视频说了 OpenAI 和 GPT-5 这么多 「坏话」,我个人其实还是非常喜欢这款产品,以及我是一个忠实用户,基本上工作、生活都离不开 ChatGPT 了。
这场发布会让我看到了 ChatGPT 朝着一个更好的 AI 全能 super app 的迈进。很多功能,在我看来,都将让我的生活和工作更加高效。
本文来自微信公众号:硅谷 101,作者:陈茜












