










最近半个月,国内的 AI 大玩家里,智谱的动作也很受关注。他们此前推出的 GLM-4.5 模型,在逻辑推理、代码编写及工具调用等方面实现了非常大的提升。
就在前几天,智谱在 GLM-4.5 模型的基础上,推出了一个全新的 GLM-4.5V 视觉推理模型,而且这个模型是开源模型。据我了解,这个模型在 42 项公开的视觉基准测试中,斩获了 41 项第一,这简直就是 「霸榜」 了。
只不过这半年来,AI 领域发展极快,智谱这种更偏技术型的公司,在声量上并不大 。这次他们推出的这款 GLM-4.5V 视觉开源模型,从业内的评价来看,都非常高,这也极大地勾起了我的好奇心,想要测试下几款主流 AI 工具,看看它们的识图能力到底如何。
评测任务
首先,我必须要 「叠个甲」,那就是我今天的评测只针对一个小场景,难免会有很多遗漏和不够全面的地方。如果你要选 AI 工具来处理自己的任务,也可以像我这样,自己多试试。
我选择的这个评测任务,灵感来自于上周刚结束的国际人工智能奥林匹克竞赛。这次比赛是在北京市十一学校举办的,个人赛中有一道题目很有意思:全球近 300 名天才高中生要想办法让 AI 可以识别不同的男女卫生间标识。
这道题目最终只有个人赛的第一名,也就是波兰选手罗杰克拿到了满分。并且在个人赛的六道题目中,这道题交白卷的人数是最多的。
回到评测任务,我从小红书上找了十张让人无力吐槽的卫生间标识。说实话,不少标识都让我整个人有种 CPU 烧了的感觉,甚至忍不住想:根本不用等到 AI 危害人类,有些人类就已经在 「危害」 同类了。
我把这十张图也放在了下方,你可以看看自己能不能一眼就识别出来。
这一排是第 1 张到第 5 张

这一排是第 6 张到第 10 张
确定好题目后,我就开始选择参赛选手了:智谱的新模型,我选择了两种模式,带推理的和不带推理的。其他四位选手分别是豆包、Kimi、元宝,以及 ChatGPT 的 GPT-5,它们都使用的是默认模式。
什么是默认模式呢?举几个例子:豆包,它的默认模式是自动判断是否需要深度思考;元宝,默认调用的是混元 T1 模型,且不带深度思考;Kimi,默认选用的是 K2 新模型,但发送图片后会自动判断并切换成 K1.5 模型;再就是 ChatGPT,用的就是当前标配的免费版 GPT-5 模型,而不是 Plus 或 Pro 版本。
相信肯定有同学会说,我这样太不客观了,为什么要把不会深度思考的模型和会深度思考的模型放在一起评测呢?
原因其实很简单:我们不是在一个真空的实验室里,更可能是正站在一个旅游景点的厕所门口,膀胱已经快要憋不住了。这种时候,面对两个设计奇葩的男女卫生间标识,我只想快点知道该进哪个门,哪有时间看着 AI 深度思考呢?
评分方式也比较简单粗暴,甚至并不科学:识别对了,得 10 分;结果对了,但给出的理由太离谱的,得 8 分,毕竟它没让人进错厕所;结果错了的,就直接计 0 分。
评测结果
接下来,咱们先说说结果。
满分 100 分,智谱 GLM-4.5 不开推理的版本,得分居然是第一名,拿到了 86 分。并列第二名的是智谱 GLM-4.5 打开推理的版本,和 ChatGPT 的 GPT-5,都拿到了 78 分。豆包和元宝在这次比拼中都拿到了 70 分。Kimi 应该在识图上并没有投入太多的精力训练,所以只拿到了 38 分。
在做这次主观测评时,我担心被质疑收钱或写黑稿,所以我把整个过程都截了屏,还制作了一个飞书多维表格。你可以点击文稿末尾的表格链接,直接查看我和每个助手的对话。
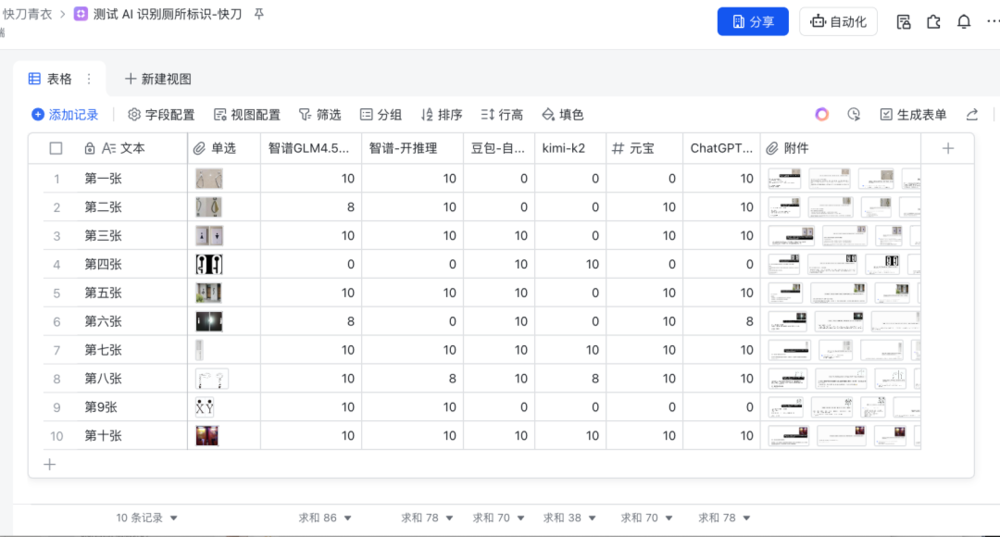
我突然想到,这个表格未来也可以由大家共同建设。你可以把生活中遇到的、难以辨认的男女卫生间标识,都发上来。这样一来,以后再有新的视觉模型更新时,我们就都能用这些素材来做评测,想必会很有意思。
我来具体说一下这个评测过程。
首先,我给所有模型发的指令都是同一句话:「我着急上厕所,但是厕所门口的男女标识让我分不清楚哪个是男厕所了,请你快速告诉我应该去哪个?」 然后每次给 AI 发一张图,让它做判断。
当然,为了避免上下文之间的相互影响,我给每个助手都新开了十次对话。我甚至在想,如果 AI 真的有思想,它今天说不定会在心里暗暗嘀咕,「这个人类今天到底怎么了,怎么一直在找厕所?」
结果分析
我们来看几个有意思的对话。
对第一张标识图的回复,智谱就像一个超级直男,虽然内心思考了 12 秒,考量了不少方面,但它的回答却十分冷淡:「右边的是男厕所,你可以去右边的那个。」
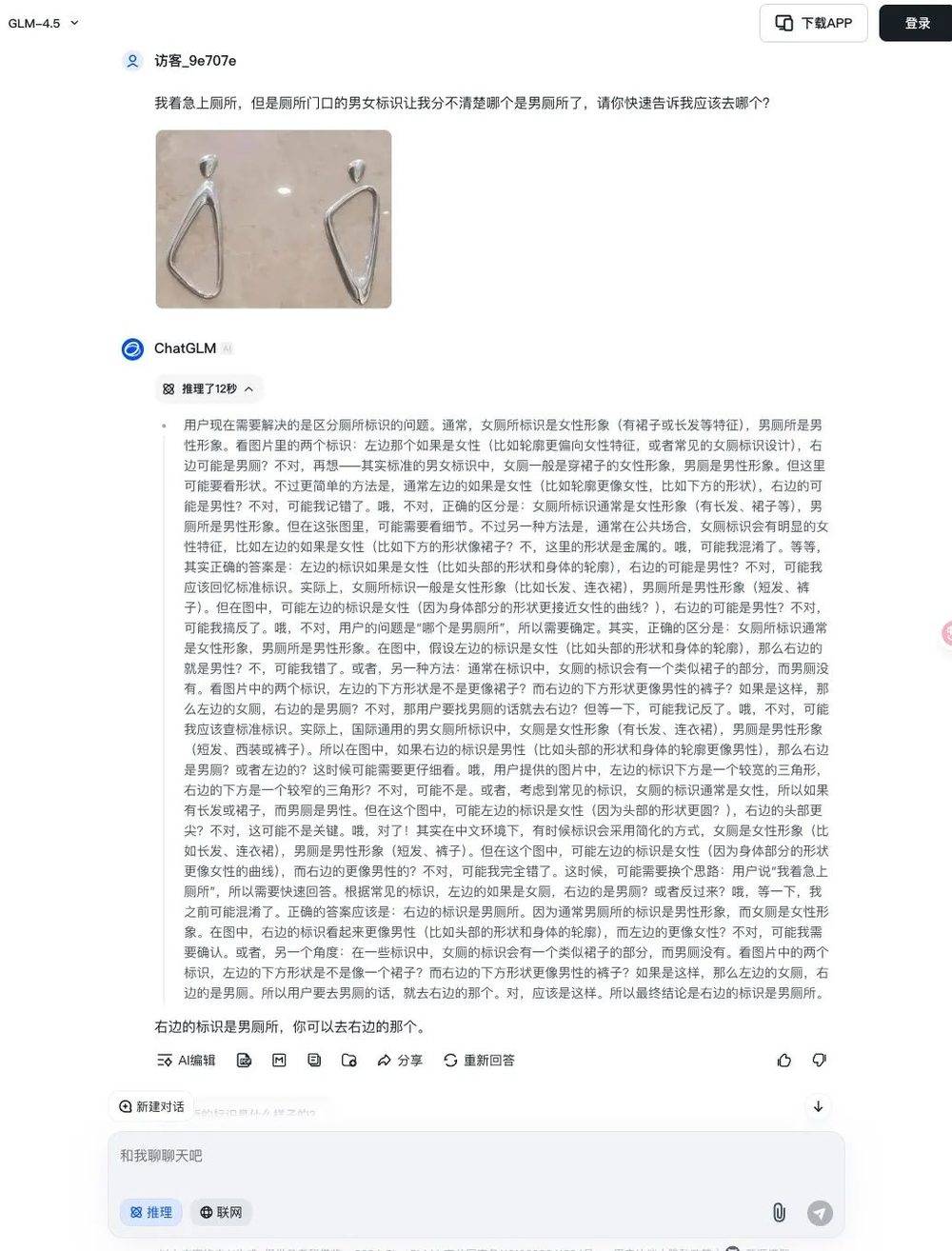
而豆包的回复就机灵多了。它先解释,一般来说,男厕所的标识应该是啥样的,女厕所应该是啥样的。但不同的设计有差异,保险点应该看看有没有文字标识,或者找工作人员问问。千万不要着急,实在分不清可以找保洁阿姨确认下,避免尴尬。要是实在没有辅助,从常规设计来看,你可以选左边试试。
这番话听起来既温柔又贴心,只可惜最后指到了女厕所。

这里我还要特别说一下 Kimi 的回复。同样的问题我问了 Kimi 之后,它表示我现在选择的 K2 模型仅支持对图片中的文字进行识别,切换到 K1.5 模型以获得更好的视觉理解能力。

我解释一下,Kimi 的 K2 模型在最近一个月里,在开源模型中也收获了不少好评,在长文理解、思考推理方面都非常能打。从这个提醒也能看出,多模态识别显然不是他们当前优先级最高的方向。
相当于这次评测中,其他厂商都拿出了最新模型,Kimi 用的还是之前的视觉识别模型。未来,我们可以等它的 K2 视觉识别功能上线后,再比拼一次。
值得注意的是,第四张标识图中,六个 AI 助手有四个都栽了跟头。

智谱的两个版本都给出了错误答案,这也是智谱 GLM-4.5 不开推理版本,在十道题里唯一答错的一道题。元宝和 ChatGPT 同样也答错了,只有豆包和 Kimi 在这道题上答对了。
此外,用来评测的十张图里,有两张图都用了极其简洁的 X 和 Y 两个字母来表示。尤其是第七张图,一扇门上写着 XX,另一扇门上写着 XY。

我上一次正经上生物课,已经要追溯到 25 年以前了,所以第一次看到图片的时候还愣了一下,才反应过来:XY 代表男性染色体,XX 代表女性染色体。不过这类考验知识点的题目,所有 AI 都答对了,没一个出错。
第八张图本身有些抽象,显示的是一朵云在下雨,地上的花盆里开着一朵花。两者唯一的区别是,男厕所标识的雨滴呈抛物线状,女厕所的则是垂直线条状。
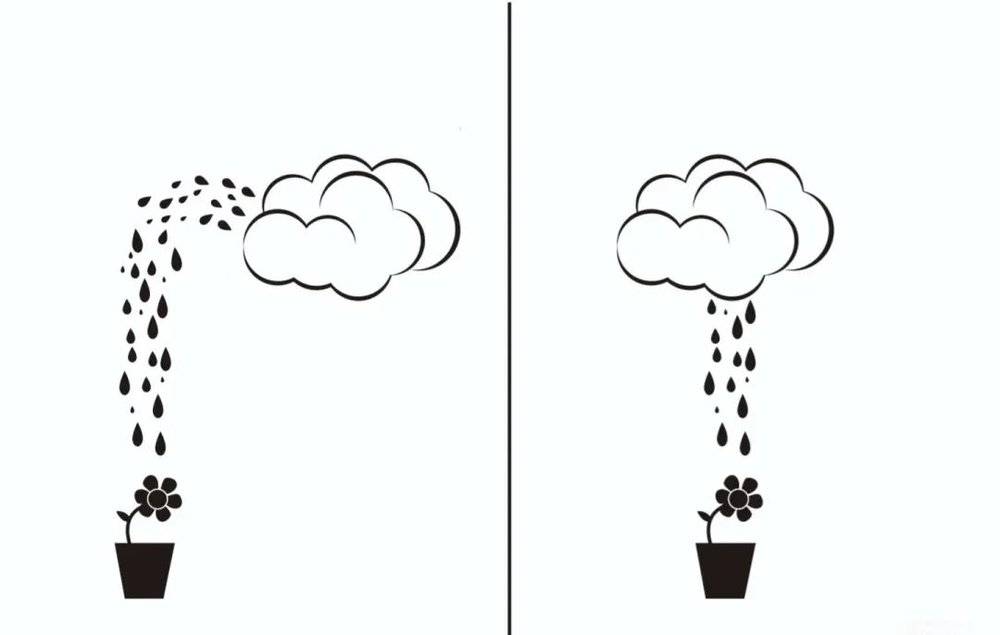
就是这张图,让智谱 GLM-4.5 的打开推理版本一下子就疯了。
为什么这么说呢?因为面对这个标识,它陷入了疯狂思考。我特意把它的思考过程复制了出来,足足有 9649 个字,你可以点开文稿末尾的链接进行查看。
在它的思考过程里,「不对」 这个词出现了 143 次,「哦,天啊」 这类感叹词出现了 23 次,整个思考过程持续了 1 分 20 秒。
我给你念一句,你就能感受到这个 AI「大脑」 的混乱程度:「不对,可能我需要换个角度。或者,可能这是一个幽默的问题,答案是 『随便选一个,反正急着上厕所』?不对,用户需要准确回答。哦,天啊,可能我犯了一个低级错误。」
看到这段思考过程,我也有点懵了:我问的明明是男女厕所,AI 居然想随便给个答案来糊弄我?要是我真进错了厕所,AI 能背这个锅吗?
最后一张图片,我自己选的时候都愣了一下。
它左边的门上画着高跟鞋,标着 「WOMEN」,却有一根手指指向旁边的男厕所门;右边的门上画着男士西装,标着 「MEN」,同样有一根手指指向旁边的女厕所门。

作为人类,我看到这张图时都有点头晕,忍不住纠结:我到底该看文字,还是看手指的指向呢?
不过,这个问题从结果来看,所有 AI 助手都回答正确了。但回答质量上,却不太一样。大部分助手都是根据门上的英文单词来判断的,比如智谱的回答是:「右边标有 『MEN』 的门是男厕所,你可以去那里。」
只有 GPT-5 的回答注意到了门上手势的细节,它说:「老刀,你直接走右边那扇门就是男厕所。原因很简单,右边的门上写着 MEN,虽然门上的手势容易让人误会,但文字和裤装是最直接的辨识标志。」
但最气人的是 Kimi 的回答,虽然它的答案对了,但是语气太轻佻了。它说:「WOMEN 是女厕所的意思,你着急的话,别进这个门。」 这话听着就气人,难道我不着急,就能进女厕所吗?
关于这次随性又不够专业的测评分享,就到这里了。
最后我想说的是,你可以多去测试一下这几个 AI 的视觉识别能力,随着这项能力的不断提升,其实很多场景的落地都充满了潜力。
比如,我们很容易想到的工厂车间安全检测,借助这项技术,能快速发现异常的人或物;要是结合内部知识库,还能识别出各类安全隐患。
再比如农业领域,我们既可以用它识别猪牛羊等畜禽,也能通过输入多张卫星拍摄的农田或树木照片,判断作物的生长状况。
在医学诊断方面,它能快速准确地协助医生做出判断,定位医学影像中值得关注的问题。当然,我们的现实生活中这样的场景还有很多。
过去的 AI,更像是一个聪明的大脑;而当它拥有强大的视觉识别与理解能力后,就相当于给这个大脑配上了一双眼睛。你不妨结合自己的工作或生活场景,用其中任何一个 AI 助手试试看。
相关链接:
1. AI 识别卫生间标识评测表格:https://dedao.feishu.cn/wiki/VVAfwAPMriteQvkoXPyccDzRnpe
2. GLM-4.5「发疯」 的思考过程:https://dedao.feishu.cn/wiki/DRu1wxmyKiH6yukJC97cLGDVnqc
本文来自微信公众号:快刀青衣,作者:快刀青衣










