














几天前,苹果在 HuggingFace 上全面开源了视觉语言模型 FastVLM 和 MobileCLIP2,再次在 AI 社区掀起震动。
这两款模型的直观特征只有一个字:快。FastVLM 在部分任务上的响应速度比同类模型快出 85 倍,并且能在 iPhone 这样的个人设备上流畅运行。但这并非一次孤立的技术秀。
与 MobileCLIP2 等开源模型一道,FastVLM 构成了苹果 「B 计划」 的核心:端侧 AI 小模型战略。
苹果亮剑小模型
用最通俗的语言解释 FastVLM。它是一个 「看得懂图、读得懂话」 的多模态模型,重点有 2 个,1 个是名字里的 「Fast」——快;另一个则是 「VLM」。
正如其名,FastVLM 最引人注目的特点就是 「快」。这种快并非简单的性能提升,而是数量级的飞跃,使其能够在手机、电脑等个人设备上实现以往需要云端服务器才能完成的实时任务。
最直观的体验是,在生成第一个 token 的响应速度 (TTFT)上,FastVLM 比同类模型 LLaVA-OneVision-0.5B 快了惊人的 85 倍,而其负责 「看图」 的视觉编码器规模却缩小了 3.4 倍。即使是其更强大的 7B(70 亿参数)版本,在与近期备受关注的 Cambrian-1-8B 模型对比时,性能更胜一筹,同时 TTFT 速度快了 7.9 倍。
FastVLM 之所以能实现速度与性能的平衡,其技术核心在于一种新型的混合视觉编码器 FastViTHD。从技术角度看,这种编码器能够输出更少的 token,并显著缩短高分辨率图像的编码时间。
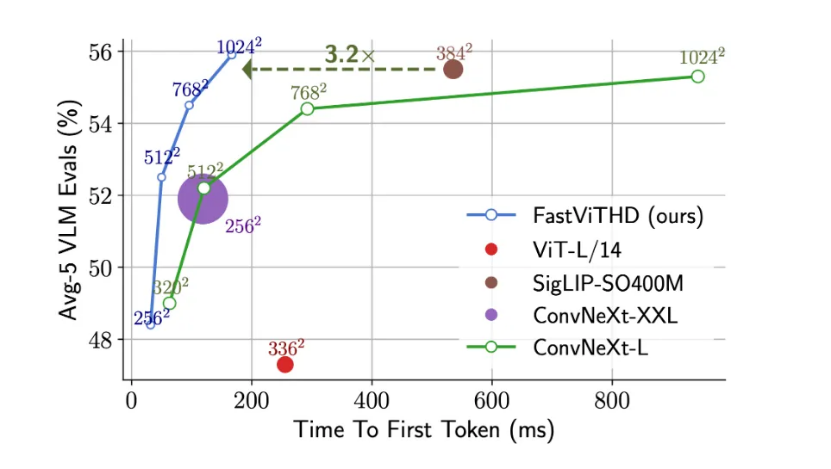
图注:FastVLM 性能表现
传统的视觉模型在处理一张高分辨率图片时,会将其分解成成千上万个小块 (patches),然后将这些小块转化成 「视觉词汇」(tokens)交由语言模型解读。图片越清晰,细节越多,产生的 tokens 就越多,这会给后续的语言模型带来巨大的计算压力,导致处理速度变慢,尤其是在手机这样的资源受限设备上。
而 FastVLM 的混合视觉编码器则结合了两种技术路径,将卷积网络和 Transformer 融合到了一起。从而,能够在不牺牲关键视觉信息的前提下,输出更少但更精华的 tokens。
因此,其作为 VLM (视觉语言模型),它不仅快,理解图像和文字的综合能力也同样出色,能够在保证速度的同时,维持极高的准确性。

图注:FastVLM 架构
目前,FastVLM 已经上线多个尺寸,包括:0.5B、1.5B、7B 版本:

凭借这样的能力,FastVLM 已经可以支持无需任何云端服务,端侧的实时浏览器字幕等功能。
目前,HuggingFace 平台 Apple 开源 FastVLM 页面已经提供了试用平台。链接如下:https://huggingface.co/spaces/akhaliq/FastVLM-7B
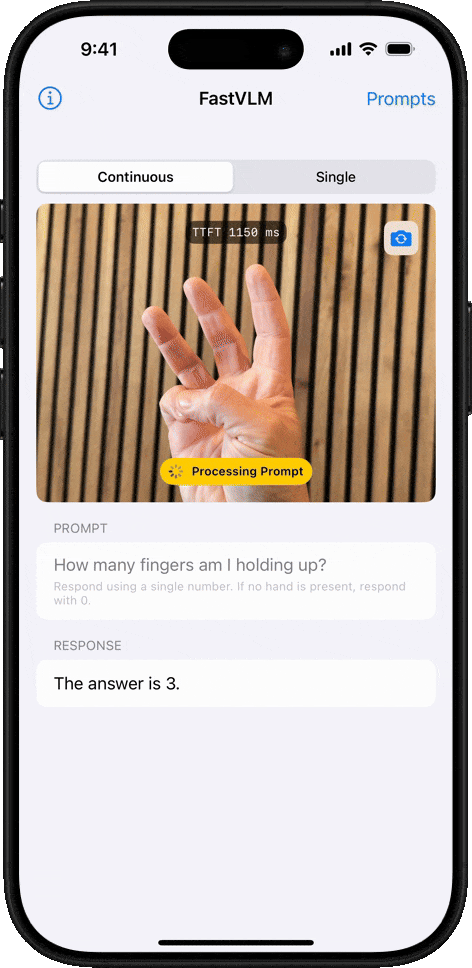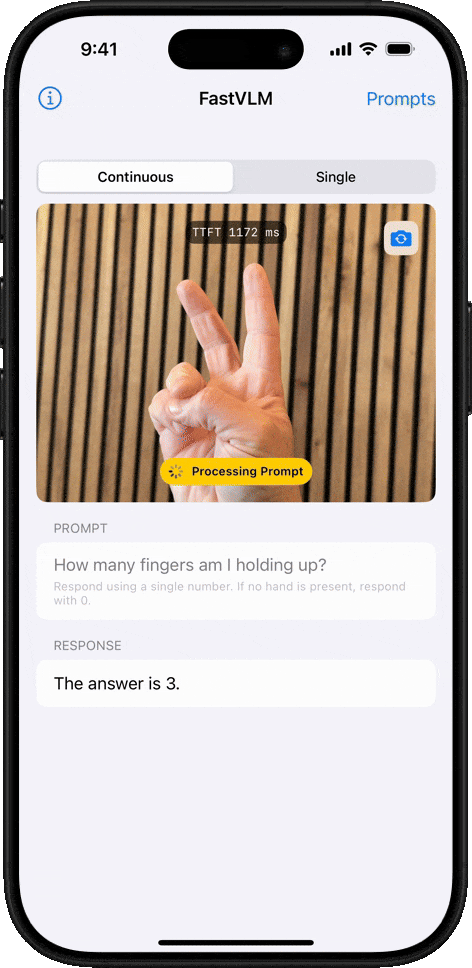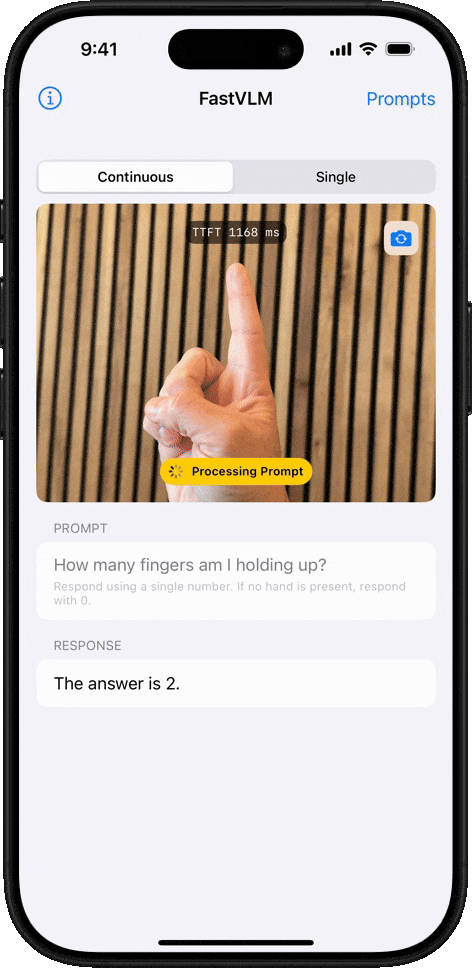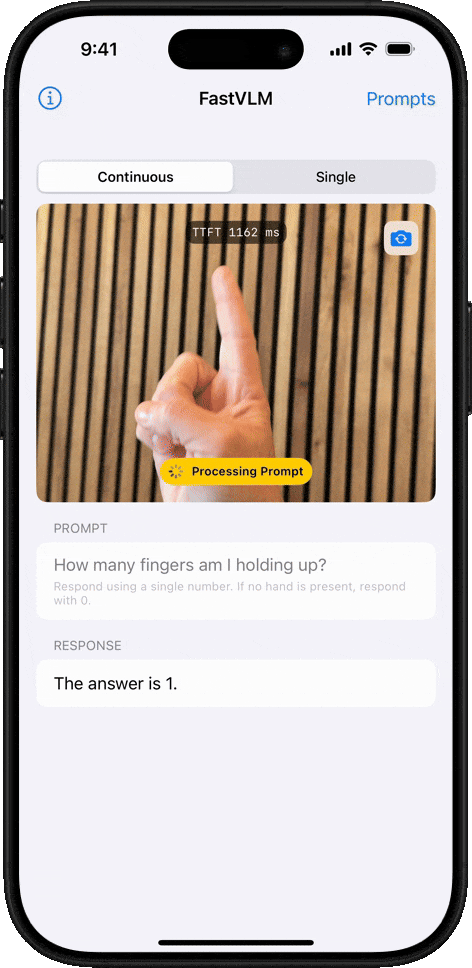
我们同样上手体验了 FastVLM 的强大功能。我们选取了近期在社交媒体上广为流传的 「马斯克计划将擎天柱 (Optimus)机器人送上火星」 的视频作为测试材料。整个过程非常直观,上传视频后,只需点击左侧的 「Analyze Video」,分析就开始了:
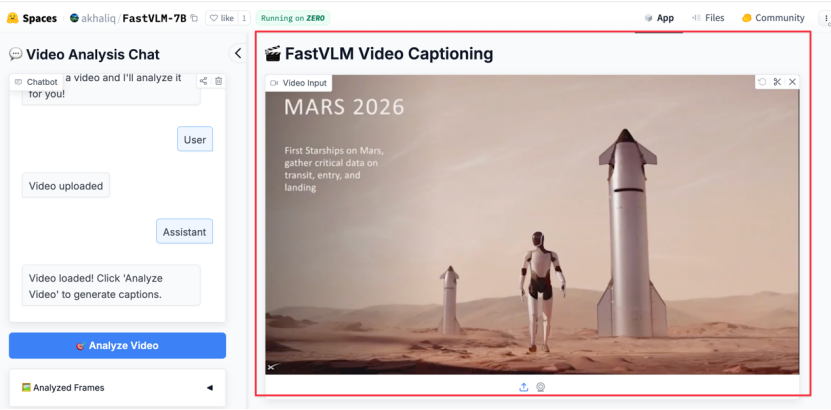
FastVLM 的处理速度确实令人印象深刻。我们粗略计时了下,单帧画面的分析时间仅在 1~2 秒,甚至更短之间,系统在不到几秒内就完成了对 8 个关键帧的提取和解读。
以下是 FastVLM 捕捉到的画面及其生成的描述:
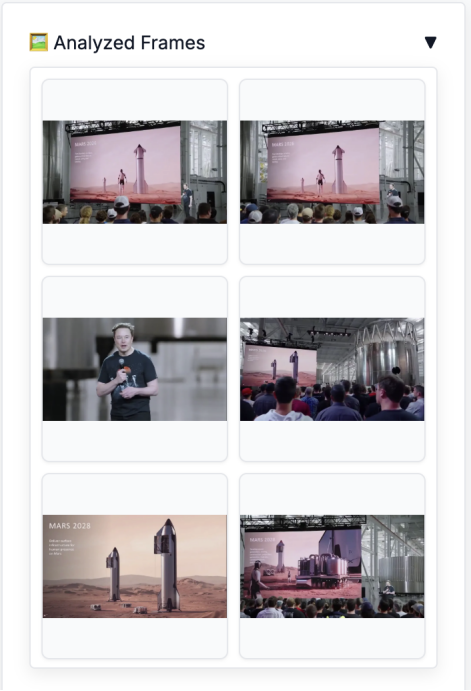
图注:FastVLM 捕捉的画面
给出的结果则是:
我将生成的画面分析结果翻译成了中文:
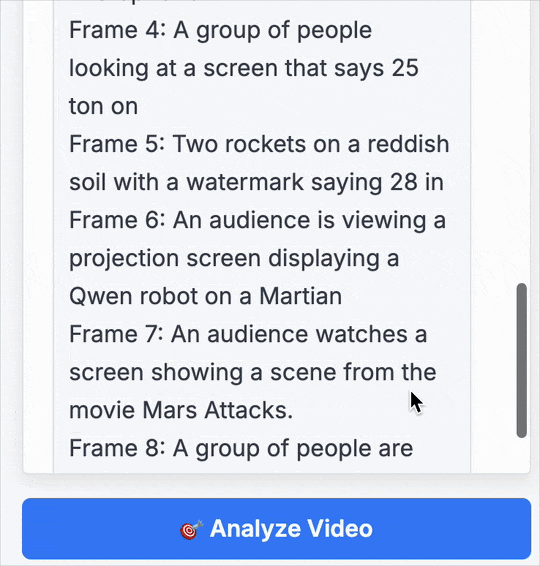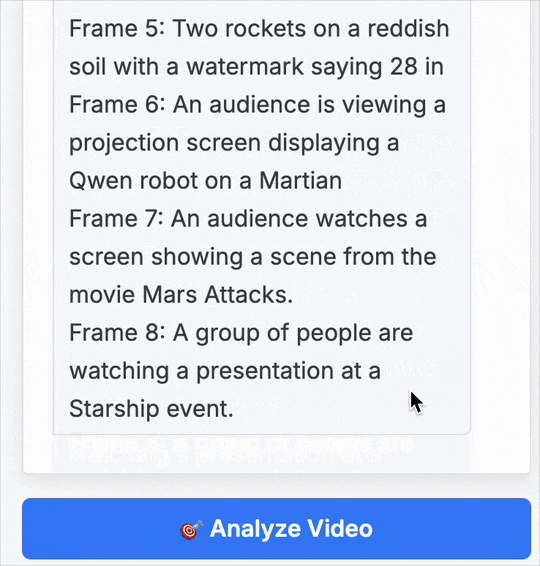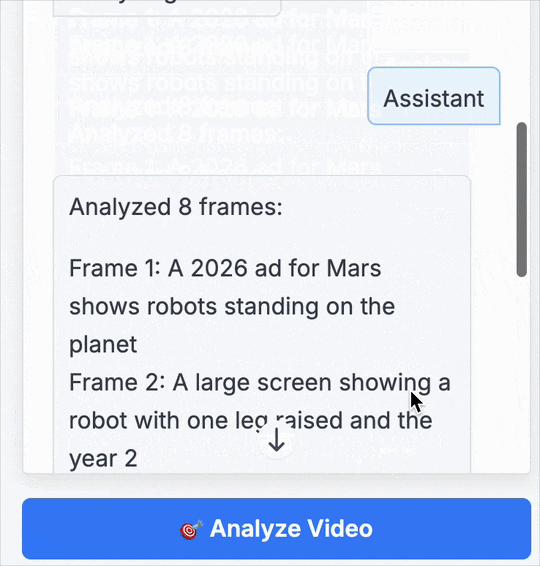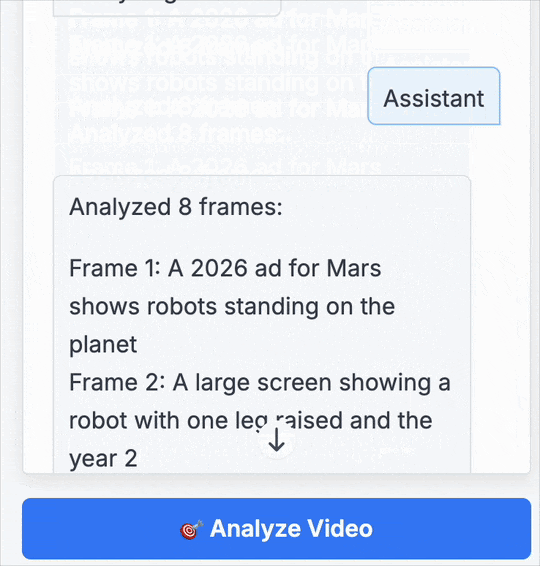
第 1 帧: 一则 2026 年的火星广告,展示了站在火星上的机器人。
第 2 帧: 一个大屏幕,上面显示着一台抬起一条腿的机器人,以及年份 「2」。
第 3 帧: 一位穿着黑色印花 T 恤的男子手持麦克风。
第 4 帧: 一群人正注视着屏幕,上面显示 「25 ton on」。
第 5 帧: 两枚火箭立于红色土壤之上,画面上有 「28 in」 的水印。
第 6 帧: 观众正在观看投影屏幕,上面显示着火星上的 Qwen 机器人。
第 7 帧: 观众在观看屏幕,播放的是电影 《火星人玩转地球》(Mars Attacks)的片段。
第 8 帧: 一群人正在参加星舰 (Starship)活动的演示。
最关键的是,你会发现,FastVLM 在追求极致速度的同时,并没有牺牲准确性。经过逐一比对,我们发现生成的描述与每一帧的画面内容都比较吻合。
除此之外,苹果同样准备了一个叫做 FastVLM-Web GPU 的项目,它可以通过摄像头实时分析视频流。你可以在下面这个位置找到它,点击即可使用:
由于它的能力很强,吸引了各路网友前来试用,也有 X 大神 @GabRoXR 搞出了很有趣的测试 Demo。比如,通过设置一个 OBS 虚拟摄像头,将其直接接入 MetaQuest 头显中,做一个实时字幕应用:

值得注意的是,FastVLM 对于本地设备的硬件能力要求非常低,比如,一个 X 网友 @njgloyp4r 仅通过 Chrome 浏览器和一块 RTX 3090 显卡,配合 OBS 虚拟相机及系统截图工具,就能手搓出一个实时识别画面的工作流:

尽管 FastVLM 相关文件在四个月前就已悄然现身 GitHub,但此次在 HuggingFace 上的全面补齐,依旧引发了业界的广泛关注和热烈讨论。
其次,FastVLM 的开源并非一次孤立的技术展示,而是苹果为其 「端侧 AI」 战略精心打造的关键一环。与 FastVLM 一同引发关注的,还有苹果最新开源的另一类兼顾低延迟与高准确度的图像-文本模型 MobileCLIP2。
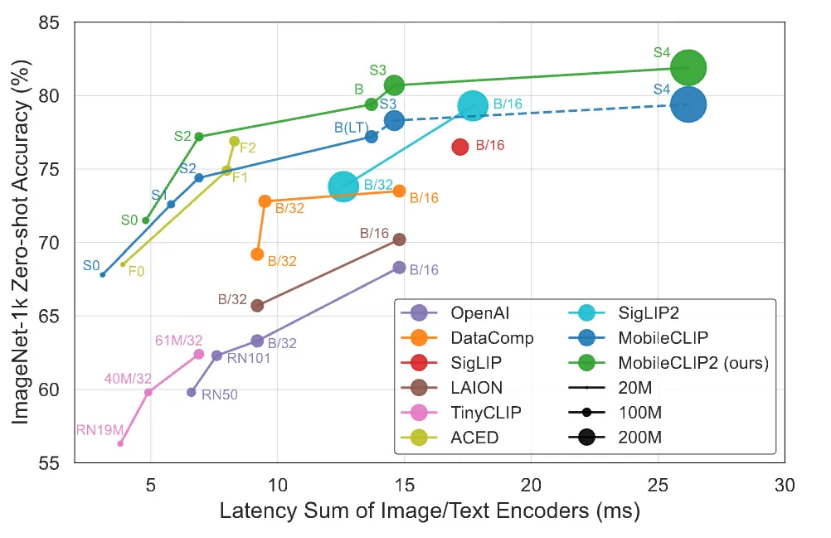
图注:MobileCLIP2 性能表现
其同样专注于在移动设备上实现低延迟与高准确度的平衡,它通过 「多模态强化训练」 构建,目标是实现在移动设备上快速响应,但仍保持优良性能。
苹果的 「AB」 计划
在过去几年汹涌的 AI 浪潮中,如果非要选一个 「AI 进展异常缓慢」 的科技巨头的话,作为全球市值最高的科技公司的苹果必然在一众用户和媒体人心中默默当选。
当其他几乎所有科技巨头都以前所未有的速度投身于大模型的军备竞赛时,苹果却在其最关键的硬件业务与 AI 的融合方向上,表现出一种外界看来近乎 「摇摆不定」 的姿态。
从最初坚持自研的神秘与沉默,到后来突然宣布与 OpenAI 合作、计划将 ChatGPT 集成到其生态系统中,苹果的每一步棋都精准地踩在了媒体、投资者和用户的 「心窝」 之上,表示 「令人看不懂」,引发了无数的猜测与讨论。
这种外界的疑虑在今年达到了顶峰。面对 Google、Microsoft、Meta 等竞争对手在生成式 AI 领域的狂飙突进,苹果不可能在稳坐钓鱼台了。尤其是在 VR/AR 的战线上,苹果 Vision Pro 虽技术惊艳但市场表现平平,面对 Meta Quest 系列的先发优势几乎是惨淡收场。在至关重要的软硬件 AI 结合上,相比其他几家,苹果更是慢到不行。

图源:@Painfully Honest Tech
重压之下,苹果终于选择正面回应。
8 月 1 日,苹果 CEO 蒂姆·库克罕见地召开了全员大会 (allhands meeting),直接回应 AI 挑战,这次会议不仅是库克对过去一到两年间苹果 AI 进展缓慢的一次正面回应,更像是一场重振军心的 「战斗宣传会」。库克在会上明确表示,苹果已经在这方面投入了 「巨额资金」,并将会推出一系列 「令人兴奋的」AI 计划。
紧随其后,一则重磅消息流出,印证了库克的决心:苹果已经在内部组建了一个名为 AKI 的团队,目标直指此前的合作伙伴也是业界标杆的 ChatGPT。
而为此类云端通用大模型打前哨战的,则是苹果在过去 1 年里不断在小模型方向作出的努力。如果说,以云端大模型为代表的 AI 是苹果的 「A 计划」,追求的是无所不能的通用智能;那么苹果则在 「偷偷地」 坚定地推进自己的 「B 计划」—— 小模型计划。
在过去的 1 到 2 年内取得了大量实质性进展。然而,这些成果往往被外界有意无意地忽略了。究其原因,由于 Scaling Law 无数次被印证有效,AI 圈子一直信奉 「大力出奇迹」,所以对小模型的进展常常并不在意。
2024 年 7 月,苹果就曾在 Hugging Face 上发布 DCLM-7B 开源模型,这款模型的发布,在专业圈层内引起了不小的震动。其性能已经逼近、超越了当时来自基础模型厂商的一众同级别同尺寸模型,像是 Mistral-7B、Llama 3 等等这说明,苹果在小模型的技术积累上,并说不上落后。
在 WWDC 2024 上,苹果宣布 Apple Intelligence 并非一个单一的、庞大的云端模型,而是由多个功能强大、各司其职的 AI 小模型所组成的矩阵。这些模型经过高度优化,专门用于处理用户的日常任务,如整理邮件、润色文稿、智能相册搜索等。
当全世界向云端大模型狂奔,苹果选择回归设备
苹果想要保住基本盘,就得在端侧打 AI 反击战。
苹果的商业帝国建立在三大基石之上:极致的用户体验、无缝的软硬件生态,以及对用户隐私近乎信仰的承诺。 这三大基石,共同决定了它的 AI 战略几乎必然走向端侧,走向小模型。
首先,隐私方面,苹果在与外界云端 AI 基础模型厂商的 「互动」 中,总是显得有些仓促应对,媒体关于接入外部 AI 能力的举措,一直质疑声不断。
比如,对于一个将 「What happens on your iPhone, stays on your iPhone」(你的 iPhone 上发生的一切,只会留在你的 iPhone 上)作为核心营销语的公司而言,把 AI 能力寄托于外部 AI 基础模型厂商,被许多忠实用户和科技评论员看来,甚至是一次 「品牌背叛」。甚至有媒体称 「苹果会保护你的隐私,而 OpenAI 则做不到」。

以至于苹果后续不得不推出了 AI 时代的隐私保护 「私有云计算」(Private Cloud Compute)等技术,也难以在短时间内完全打消市场的疑虑。
再把视线转向国区。外界一直在猜:苹果到底会牵手哪家本土 AI 基础模型厂商?BAT、字节,还是新晋的 DeepSeek?
最终,有消息称百度或成为合作对象。但很快,路透社的一则报道把争论推向高潮——苹果与百度在隐私问题上出现了严重分歧。
百度希望留存并分析来自 iPhone 用户的 AI 查询数据,而苹果的严格隐私政策则一概禁止此类数据收集与分析。两者在 「用户数据使用」 方面产生明确分歧。

可以说,在数字时代,隐私是苹果最锋利的武器。而将 AI 计算尽可能留在设备端,是捍卫这一承诺的关键技术路径之一,尤其是图像视频模态数据。
你想找一张 「去年夏天在海边和狗玩的照片」。在端侧 AI 模型上,这个搜索过程完全在你手机本地的芯片上完成。你的私人照片、地理位置、甚至你和谁在一起的这些高度敏感信息,从未离开你的设备,也从未上传到苹果的服务器。这与需要将照片 (或其特征)上传至云端进行分析的方案,在隐私保护上有着极大的区别。对苹果而言,选择端侧就能够运行的小模型,首先是一道 「商业伦理题」,其次才是一道 「技术选择题」。这是对其商业模式的根本性巩固。
除了隐私保护之外,用户体验也是苹果下大力气集中攻坚小模型的动力之一。一直以来,苹果产品的核心竞争力,在于 「一旦用了,就难回到之前」 的流畅体验。端侧 AI 是实现这种极致体验的保障。
云端 AI 总会受到网络状况的制约,一个简单的指令来回传输可能需要几百毫秒甚至更久,这种 「卡顿感」 会瞬间打破沉浸式体验。用户的设备可能在任何地方,比如信号不佳的地下室、万米高空的飞机上、或是异国他乡没有漫游信号的角落。一个依赖网络的 AI 功能,在这些场景下会立刻 「失灵」,而端侧 AI 则能保证核心智能 「永远在线」。自第一代 iPhone 诞生以来,苹果产品最深入人心的标签就是 「可靠感」。用户需要一种永远在线的 「可靠感」。
其次,从性能表现来看,在公众和部分业界的认知中,大语言模型 (LLM)的参数量似乎与 「智能」 程度直接挂钩,形成了一种 「越大越好」 的普遍印象。然而,在实际应用,尤其是在需要高度专业知识和精准度的垂直细分场景中,这种看似无所不能的 「通才」 大模型,其表现却不一定比经过精细打磨的 「专才」 小模型更好。
最后,驱动苹果走向端侧 AI 的,还有一笔深藏在硬件迭代背后的、必须算清楚的 「经济账」。近年来,一个让用户和评测机构都普遍感受到的现象是,iPhone 的 A 系列和 Mac 的 M 系列芯片性能越来越强大,其每一代之间的性能突破,常常让用户觉得 「性能过剩」 了。一边是硬件算力近乎疯狂地增长,另一边却是大多数用户在日常应用 (如社交、视频、游戏)中,无法体验到同等速率提升的感知。

如何有效吸收并转化这种看似溢出的边际性能,是苹果必须解决的核心问题。如果计算任务分配到用户自己的设备上,利用设备上本就强大的 A 系列/M 系列芯片,对苹果来说,是最经济、也最可持续的商业模式。
如果把视线从苹果移开,会发现行业内对小模型的兴趣确实在普遍升温。但这并不意味着所有公司都在追逐同一个目标,更准确的理解是:不同公司基于其核心业务模式,对小模型有着截然不同的诉求。
像是被戏称为 AI 厂商 「军火库」 的英伟达对小型语言模型的重视持续升级,在其最新研究中认为:小模型是 Agent 的未来。而众多 AI 初创公司同样开始选择小模型,作为一种务实的某一小块垂直市场的切入策略,像是美国医疗版 ChatGPT —— OpenEvidence 等等。在通用能力上,它们难以与大厂的旗舰模型相抗衡。因此,它们选择专注于特定行业,如医疗、金融、法律等,利用小模型易于在专业数据集上进行微调的优势。
结尾
放眼整个行业,虽然对小模型的兴趣正在升温,但没有哪家公司像苹果一样,将其提升到生死存亡的战略高度。
过去几年,当 ChatGPT 横空出世,当微软将 Copilot 融入全家桶,当谷歌的 Gemini 迭代频繁,整个科技行业以前所未有的速度冲向下一个时代时,那个市值最高、手握最多现金的苹果,却像一个没跟上进度的差生,显得异常沉默和迟缓。
可以说,面对这场 AI 差生危机,苹果的自救之路清晰而务实:用 「A 计划」 补齐短板,避免被时代淘汰;同时用 「B 计划」 发挥长处,在自己最擅长的领域,即硬件端侧,打一场翻身仗。
本文来自微信公众号:直面 AI,作者:涯角,编辑:胡润












