

















【文章来源:techweb】
【TechWeb】9 月 30 日消息,国庆假期前夕,AI 圈被一枚 「价格炸弹」 惊醒,DeepSeek 再次挥舞降价大刀,让开发者和竞争同行们措手不及。
9 月 29 日晚间,DeepSeek 正式发布 DeepSeek-V3.2-Exp 模型,并宣布 API 调用价格大幅降低,输入百万 Token 价格降至 2 毛钱,输出价格直降 75%,被业界称为 「价格屠夫」 再挥刀。
这波突如其来的 「节日攻势」,恰逢国庆长假前最后一个工作日,让众多本计划休假的 AI 开发者和模型评测人员纷纷哀嚎——这个假期,恐怕要淹没在新模型的测试与迁移工作中了。
价格屠夫来了
DeepSeek 此次的价格调整堪称 「血腥」。
具体来看,输入价格上,缓存命中时从 0.5 元/百万 tokens 降至 0.2 元/百万 tokens,缓存未命中的价格则从 4 元/百万 tokens 降为 2 元/百万 tokens。
最令人震惊的是输出价格,从 12 元/百万 tokens 直接降到了 3 元/百万 tokens,幅度高达 75%。
这一价格体系让 DeepSeek 在众多大模型中脱颖而出,成为名副其实的 「价格屠夫」。
横向对比来看,国内外主流大模型的 API 价格普遍远高于 DeepSeek-V3.2-Exp 的新定价。
例如,Anthropic 刚刚发布的 Claude Sonnet 4.5 定价仍维持在每百万 tokens 3 美元和 15 美元 (输入和输出)。
如果按当前汇率计算,仅输出价格就是 DeepSeek-V3.2-Exp 的 30 倍以上。
在国内市场,智谱 AI 等厂商的定价也显著高于 DeepSeek 新价格。
DeepSeek 这种激进的价格策略,无疑将给行业竞争对手带来巨大压力。
架构创新带来降价空间
如此大幅度的降价,并非简单的价格战,而是基于坚实的技术进步。
DeepSeek-V3.2-Exp 是一个实验性版本,作为迈向新一代架构的中间步骤,在 V3.1-Terminus 的基础上引入了 DeepSeek Sparse Attention(一种稀疏注意力机制)。
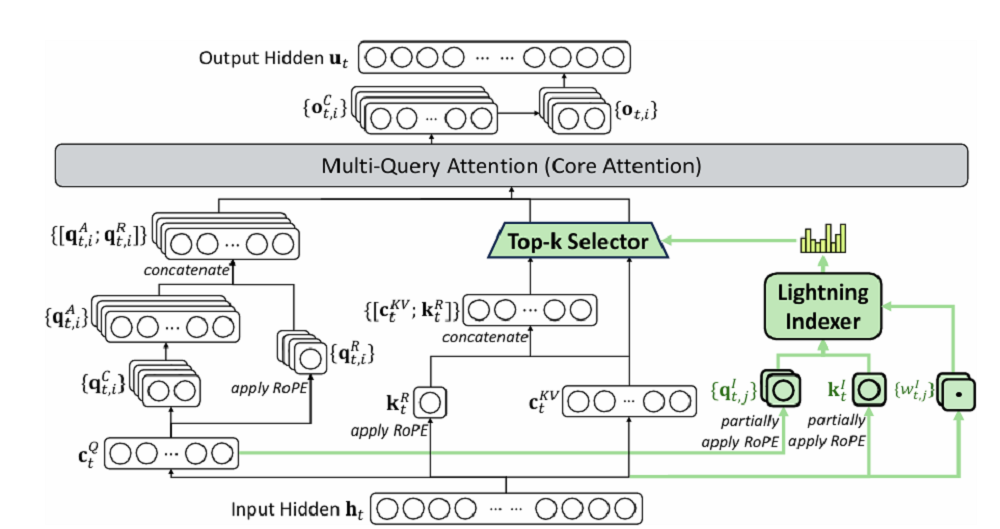
DeepSeek-V3.2-Exp 架构图
简单来说,由于实现了细粒度稀疏注意力机制,在几乎不影响模型输出效果的前提下,可以实现长文本训练和推理效率的大幅提升。
正是这一技术突破,使得 DeepSeek 能够大幅降低服务成本,从而为 API 降价提供了充足空间。
为了严谨评估引入稀疏注意力带来的影响,团队将 DeepSeek-V3.2-Exp 的训练设置与 V3.1-Terminus 进行了严格对齐。
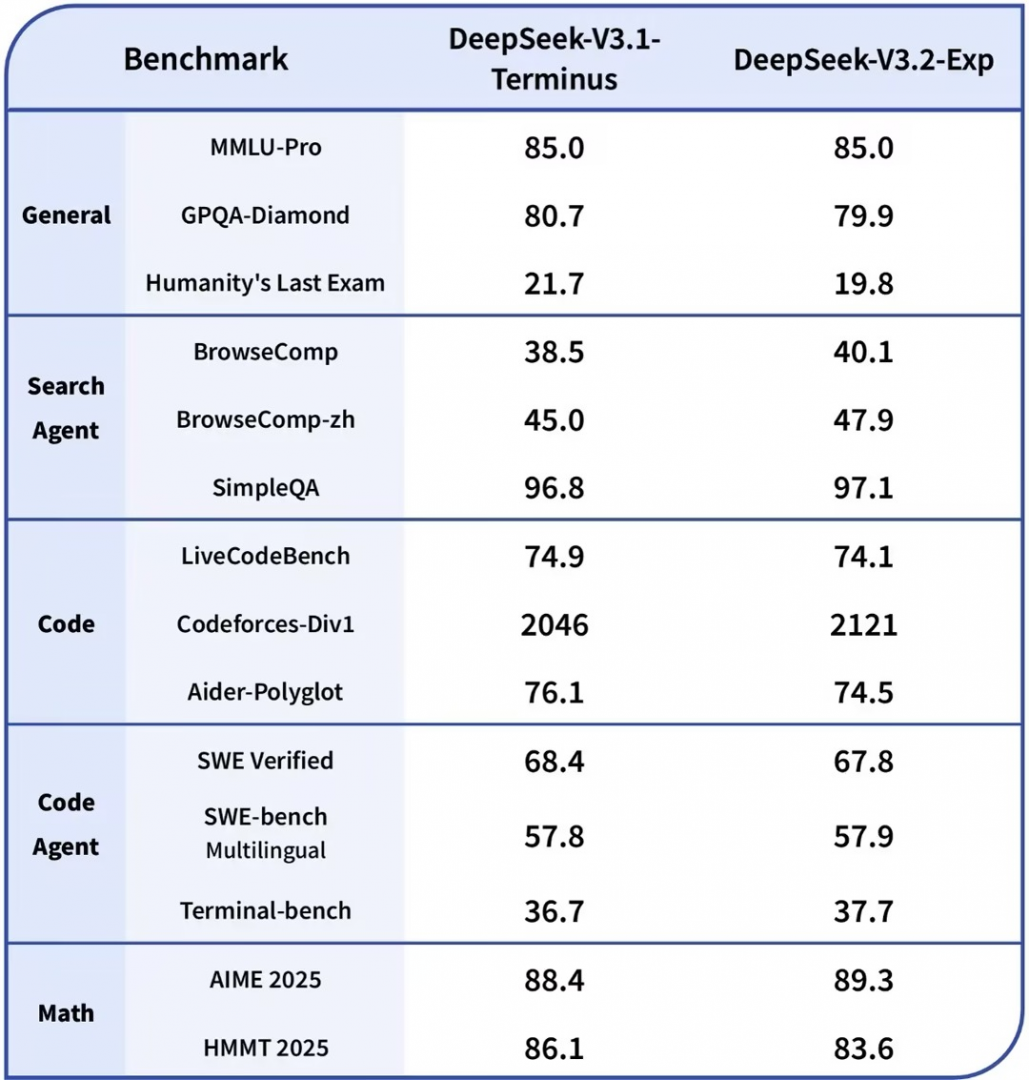
在各领域的公开评测集上,DeepSeek-V3.2-Exp 的表现与 V3.1-Terminus 基本持平。甚至在部分任务 (如数学推理 AIME、编程 Codeforces、浏览器操作 BrowseComp) 上还有小幅提升。
群雄逐鹿国庆前
DeepSeek 的这波 「节日攻势」 并非孤立事件,而是近期大模型密集发布潮的一部分。
与此同时,今天,大洋彼岸的 Anthropic 也发布了 Claude Sonnet 4.5,称其为公司有史以来最强大、最对齐的 AI 模型。
该模型在编码、推理、数学和现实计算机使用方面都有重大进步。
计划近期推出新模型的也不少。就在 29 日,智谱 AI 也在其官网上将主力模型 GLM-4.5 标识为 「上一代旗舰模型」,预示着 GLM-4.6 即将发布。
三家大模型厂商同时选择在 9 月 29 日这一时间点前后发布新品,显然都希望抢占国庆假期 (或北美市场) 的心理高地,打一场精心策划的 「节日战役」。
国内厂商火速适配,国产 AI 芯片股沸腾
面对 DeepSeek 的快速迭代,国内硬件厂商表现出惊人的响应速度。
在 DeepSeek-V3.2-Exp 发布同日,寒武纪即宣布同步实现对 DeepSeek-V3.2-Exp 的适配,并开源大模型推理引擎 vLLM-MLU 源代码。
寒武纪表示,通过 Triton 算子开发实现了快速适配,利用 BangC 融合算子开发实现了极致性能优化,并基于计算与通信的并行策略,再次达成了业界领先的计算效率水平。
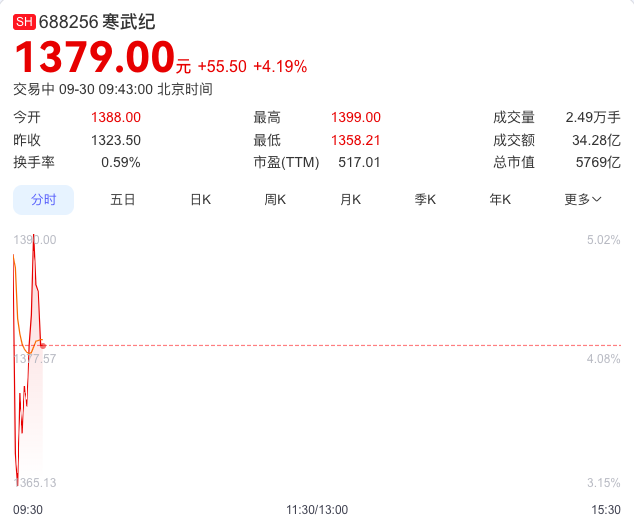
今日开盘,寒武纪股价大涨超 4%。
华为计算发文宣布,昇腾已快速基于 vLLM/SGLang 等推理框架完成适配部署,实现 DeepSeek-V3.2-Exp Day 0(第零天) 支持,并面向开发者开源所有推理代码和算子实现。
华为云也首发上线了 DeepSeek-V3.2-Exp,还使用 CloudMatrix 384 超节点为该模型提供推理服务。
同样,海光信息也宣布其 DCU 实现无缝适配+深度调优,做到大模型算力 「零等待」 部署。
海光信息表示,基于 GPGPU 架构强大的生态优势,与编程开发软件栈 DTK 的特性,DeepSeek-V3.2-Exp 在海光 DCU 上展现出优异的性能。
这种 「Day 0 适配」 现象,一方面体现了国内 AI 生态链的成熟度,另一方面也显示出硬件厂商对 DeepSeek 模型的重视程度。
开发者哀嚎:国庆假期恐难轻松
对于 DeepSeek 们带来的这一波节日攻势,最 「悲喜交加」 的莫过于广大开发者和模型评测人员。
此次更新距离上一版本 DeepSeek-V3.1-Terminus 的发布仅隔一周, DeepSeek 迭代速度的显著提升。
这种快速迭代虽然让开发者能持续获得更先进的模型,但也带来了巨大的适应压力。
一位开发者在新模型发布帖下留言道:「刚刚才适配完 V3.1-Terminus,现在又要开始迁移到 V3.2-Exp,这个国庆假期计划又要泡汤了。」
还有开发者整理出了 DeepSeek 历次模型发布时间与节日时间的相隔天数表:

也有开发人员笑称,「商场如战场,DeepSeek 节日攻势是阳谋。其他厂商节日休假,他节前发一波,同行员工放假追赶不了,假期让人们讨论舆论发酵。」
模型评测人员同样面临巨大挑战。不仅需要测试 DeepSeek-V3.2-Exp 的各项性能,还要对比分析智谱 GLM-4.6 和 Claude Sonnet 4.5 的表现,工作量大增。
模型评测人员自嘲 P 的梗图也来了:

更为复杂的是,V3.2-Exp 作为一个实验性版本,开发者需要在性能提升与稳定性之间做出权衡。
虽然 DeepSeek 表示团队已通过严格训练对齐确保模型表现稳定,但实验性版本本身仍可能存在不确定性。
这个国庆假期,AI 开发者们注定无法轻松。当别人在景区排队时,他们可能在为模型迁移调试代码;当别人享受家庭团聚时,他们可能在对比各个新模型的性能指标。
然而,DeepSeek 的 「小步快跑」 战术,确实推动着整个行业以惊人速度向前发展。V3.2-Exp 展示了通过算法和架构的创新,能够在基本保持性能的同时,实现效率的跨越式提升。这获将预示着 「效率革命」 将成为未来大模型发展的重要方向。
大模型竞赛正进一步向纵深发展,成为一场 「全能赛」,而不再是单点技术的比拼。











