
















文丨阑夕
IDC 有个报告是我从去年就开始注意的:中国大模型公有云服务市场分析,这是对国内 AI 产业 「商品化」 最客观也是最真实的数据反馈。它直接反映了大模型的应用规模,而不是把 IaaS、PaaS 打包一起统计,可以说是 tokens 经济最核心的指标。
比如去年中国整个公有云的 Tokens 调用量几乎是从无到有的飙升到了 114.2 万亿次,已经呈现出了爆发趋势,前天 IDC 又更新了今年上半年的报告,Tokens 的调用总量达到 536.7 万亿次,半年的时间干了去年全年接近 5 倍的活儿。
这张环比数据表的信息量很大,可以看到 2 个异军突起的增长拐点,分别在 2024 年 7 月和 2025 年 2 月,这两个时间发生了什么事?
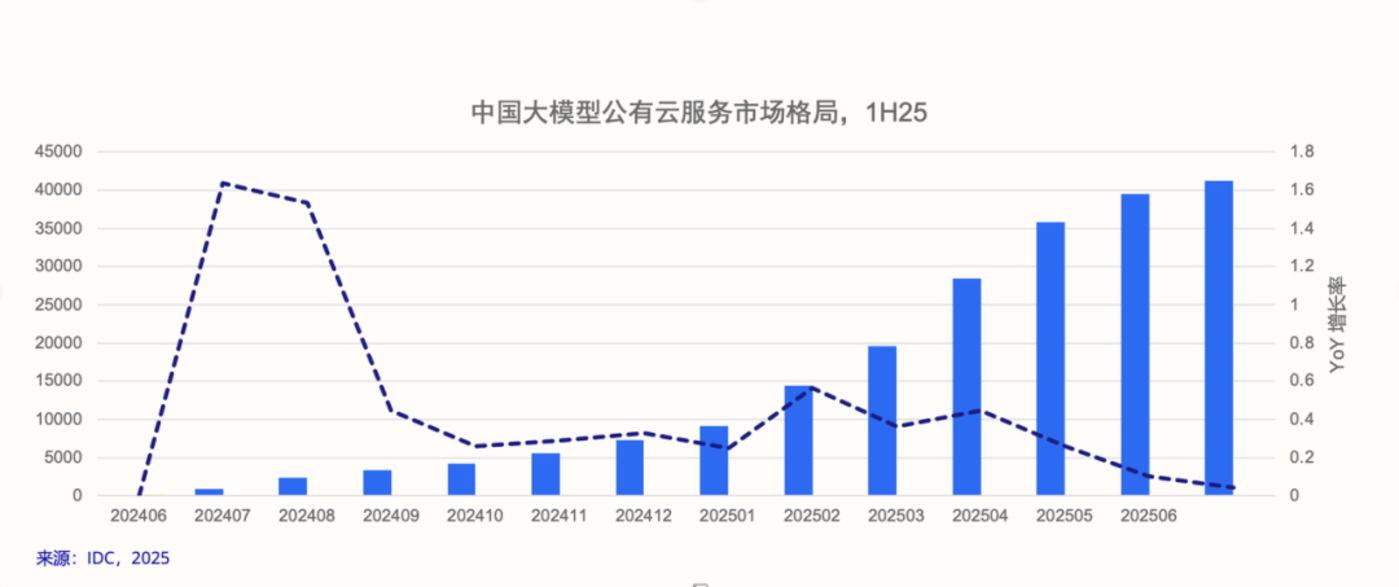
2024 年 7 月,豆包掀起大模型降价风潮的影响出现,因为把旗舰模型的计费标准从 「几分钱」 降低到 「几厘钱」,几乎是以一己之力凭空创造出了大模型公有云这个市场;
2025 年 2 月,DeepSeek-R1 全球爆火,不但打响了大模型领域的成本革命,也把 AI 云的负载压力从预训练切换到了推理,从此开源模型百花齐放,进一步促进了模型商品化的渗透率。
整个连锁反应的结果,就是 MaaS(模型即服务) 这种商业模式的拔地而起,以及最早布局 MaaS 的火山引擎,现在拿到了 49.2% 的市场份额,相当于全行业的半壁江山。注意,这个统计并不包括豆包、抖音等字节内部产品,完全是外部企业客户的调用量。
当然,MaaS 只是 AI 云的赛道之一,基于统计口径的不同,阿里云、百度云也都能在 IaaS、PaaS 等赛道拿到另外的第一名,但就含金量而言,MaaS 是最能证明大模型行业发展情况的晴雨表。
因为 MaaS 的调用量大,也够直接,模型好不好用、该怎么改的评测集,都是只有通过调用才能得到的信息,卖 GPU 是拿不到这类数据的,所以火山引擎从一开始就是把 MaaS 作为 AI 云的核心目标,这对兄弟部门的豆包也有帮助:
「大的使用量,才能打磨出好模型,并且大幅降低模型推理的单位成本。」
MaaS 是一个边缘创新的典型产物,因为营收和利润的起点都很低,传统云厂商都不太看得上,还是卖算力最赚钱,像是甲骨文这种千亿美金级别的锁单带动股价飙涨,才是聚光灯下的主流叙事。
但是对于开发者来说,原生化的 AI 云才是刚需,去买算力部署模型,门槛天然就高,比如我们都知道,DeepSeek 已经是大模型里的价格屠夫了,但要训练一套完整的 DeepSeek MoE 模型,至少需要 320 张 GPU,这就不是普通开发者能说上就上的。
所以 MaaS 这种群众路线的服务才越来越受欢迎,它相当于一家模型商店,把市面上的模型都封装到了云上,开发者不必关心技术细节,只需按量付费,直接调用模型的核心能力——文本生成、图像识别、语音转换等——为己所用。
有个对 MaaS 模式的体验形容特别恰当:拎包入住,丰俭由人。
Quest Mobile 在 2025 中国移动互联网半年大报告里也提到过一个点,在国内的 AI 应用侧,插件产品的规模要明显高于原生产品,什么意思呢,就是大家期待的杀手级 App,可能并没有那么快出现,与此同时,AI 又已经变得无处不在了,以新功能的形式。
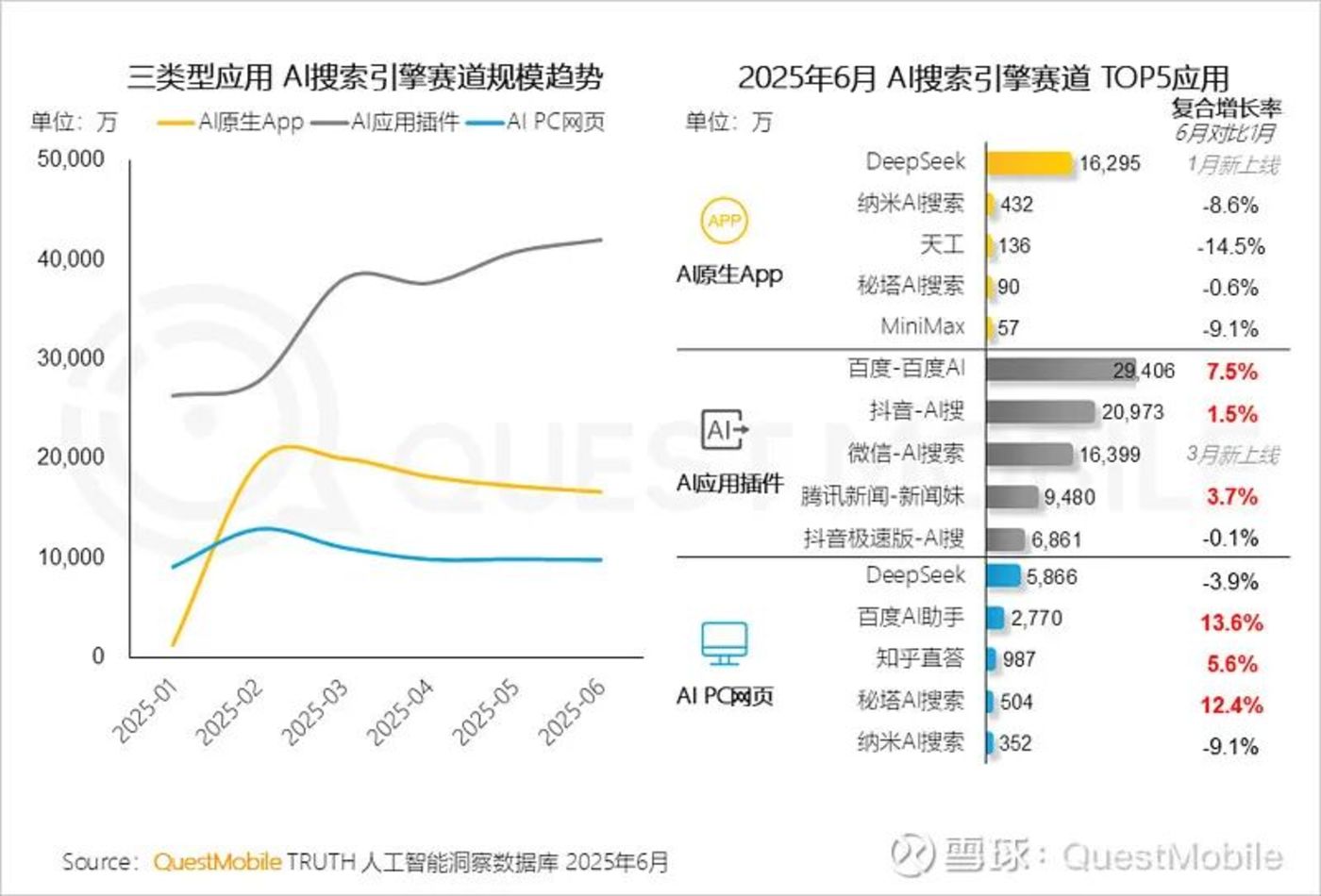
在这个渗透过程里,MaaS 市场就是最大的幕后功臣,一个社交产品的开发者,如果想要新增一个 AI 头像的绘制功能,完全可以不用重复造轮子,专门训练一个图片模型出来,而是可以像去超市购物那样,在 MaaS 市场里挑一个价格和性能最适合的,然后用接口的方式加到自己的产品里,即开即用。
美国 BI 平台 Databricks 的负责人今年也说过来自业务侧的反馈:「大多数企业并不想成为 AI 专家,他们只是需要开箱化的 AI 解决方案,而且微调和管理开源模型的复杂性对他们而言依然是一个难以跨越的门槛。」
所以像是 OpenAI 和 Anthropic 在面对免费平替的开源模型时还是非常能打,而拥有企业级服务经验的 Salesforce 和 Oracle 也在老树新芽般的高速增长,模型的原始智能水平固然重要,但更值钱的地方在于它驱动产品的质量和可用性。
某种意义上,MaaS 才是真正的大模型竞技场,像是火山引擎之所以占有率独一档,就是因为它能汇聚市面上最新、最领先的模型,还是用超市的比喻来理解,就是供应链的竞争力制胜,比如 Google 的新图片模型 nano-banana 刷屏之后,唯一能跟上硬刚的,就是字节的 Seedream 4.0,刚刚登顶 LMArena,而在火山引擎,这些顶级模型都在摆货架上 「予取予求」。
而且即便有微调和训推需求,火山引擎的 Infra 效率也是行业领先的,像是 DeepSeek-V3.1 这种开源模型在火山引擎上的表现指标也非常漂亮,这些都会最终体现到开发者的体验端,形成用量越多、进步越快的正循环。
前几天看到有条推文,说 OpenAI 曾经明确表示 GPT-4o、o1、o3、o3-mini 这样说命名对用户来说太不友好了,要用 GPT-5 来做统一和简化,现在来看,这话 OpenAI 只做到了一半,确实只有 GPT-5 一个模型了,然而我们看到迎面走来的方阵分别是:GPT-5、GPT-5 auto、GPT-5 thinking、GPT-5 pro、GPT-5-mini、GPT-5-nano⋯⋯
本质上,模型商品化的主要瓶颈,还是 Tokens 不够用,于是不得不人为设置各种档位,在让大模型变成自来水那样按需取用的生活资源这件事情上,MaaS 平台的用武之地和长期价值,一定会与日俱增。
前几个月我还在说,基于 Google 的 Q2 财报,Google 云 5 月的 Tokens 调用量是 480 万亿次,到了 7 月就涨到了 980 万亿次,不但增长极高,而且单月就已经相当于去年中国公有云总计调用次数的 8 倍之多了。
但在对齐比较对象之后,就会发现如果让豆包 「出战」,在规模上甚至是可以和 Google 正面硬刚的:
火山引擎在 6 月的一次大会上披露过,截至 2025 年 5 月,豆包大模型的日均 Tokens 调用量是 16.4 万亿次,拉到月均来算,就是 500 亿次以上,比同期的 Google 只多不少。
换句话说,这个行业还没有到冲刺的阶段,但头部大模型厂商都已经跑出了冲刺的速度,增长速度一个比一个吓人,云上一日,人间一年,我就感觉到快。
你们也可以参与预测一下,半年后 IDC 公布 2025 年全年中国大模型公有云的 Tokens 调用量时,会出现一个什么量级的数字?











